2015
Blog: Make your own Parkrun barcode [Sunday 18th October 2015]
Parkrun, a popular running community, uses
barcodes to identify runners. Runners can print their own code (many laminate it, so it survives the rigors of the race and the elements) or
buy various tokens like keyfobs or wristbands or a running shirt with the barcode printed on it. One less thing to carry, but one more bill to pay.
Or you can create our own barcode, and maybe mess around with it. The Parkrun runner barcode is just the runner's unique ID number, encoded as a Code 128 (code set B) barcode - as far as I know the format is a single letter and 6 or 7 digits.
There's plenty of software that can print barcodes - for example, you can use GNU barcode to generate one:
barcode -b A9876007 -e128b -o barcode.ps
Just for fun, you can write your name on top of the barcode - as long as you leave enough space unmolested for the barcode reader to scan. This script uses
Imagemagick to do that:
#!/bin/bash
barcode -b A9876007 -e 128b | \
convert -density 300 \
- \
-flatten \
-crop 630x360+0+2920 \
-font Ubuntu-Bold \
-fill DarkRed \
-stroke white \
-strokewidth 4 \
-pointsize 21 \
-annotate +14+3010 'Parkrun Paul' \
\
out.png
which produces a barcode like this

You can print that out (on an A4 printer), to the same scale as the official Parkrun barcodes generated by their website, with this command:
lpr -o scaling=14 out.png
2014
Blog: PyCrypto's PBKDF2 with an alternate HMAC algorithm [Monday 5th May 2014]
The documentation for PyCrypto's
implementation of the
PBKDF2 (Password-Based Key Derivation Function 2) scheme isn't super clear
about how to use an alternate hash function for the pseudorandom function. Here's a little example I've cooked up.
One needs to wrap PyCrypto's own HMAC with a little function that handles the password and salt given by PBKDF2 and which emits the digest of the resulting hash. This example illustrates using the
basic hash functions available from PyCrypto itself (several of which aren't suitable for practical use, and are just included here as examples):
#!/usr/bin/python3
from binascii import hexlify
import Crypto.Protocol.KDF as KDF
from Crypto.Hash import HMAC, SHA, SHA224, SHA256, SHA384, SHA512, MD2, MD4, MD5
import Crypto.Random
password = "A long!! pa66word with LOTs of _entropy_?"
for h in [SHA, SHA224, SHA256, SHA384, SHA512, MD2, MD4, MD5]:
hashed_salted_password = KDF.PBKDF2(password,
Crypto.Random.new().read(32), # salt
count=6000,
dkLen=32,
prf=lambda password, salt: HMAC.new(password, salt, h).digest())
print ("{:20s}: {:s}".format(h.__name__,
hexlify(hashed_salted_password).decode('ascii')))
Blog: Did Boris Yeltsin inspire Game of Thrones? [Sunday 20th April 2014]
In George R. R. Martin's fantasy series
A Song of Ice and Fire, the kings of the unfortunate land of Westros (not Nova Scotia) sit on a throne made from hundreds of swords, which is supposed to look like
this. The swords are those
of an ancient king's enemies, and the uncomfortable chair they comprise serves to remind the incumbent monarch of the precarious, painful nature of lordship. It's a neat analogy; but did Martin invent it, or was it (of all unlikely fantasy authors) Boris Yeltsin?
In a speech on TV in 1993, three years before A Game of Thrones (the series' first book) was published, Yeltin said "You can build a throne with bayonets, but it's difficult to sit on it" (reference). The normally pretty thorough TV
tropes doesn't have like it that predates either (trope: Throne made of X) - obviously both Yeltin's and Martin's thrones owe a lot to the Sword of Damocles.
To Martin, of course, it's a fun fantasy in a magical land of boobies and dragons. To Yeltsin thrones were no abstract plaything - for him, as for Henry VI, uneasy lies the head that wears a crown. Perhaps uneasy sits the bum underneath it too.
Blog: Why you want a driverless car: not to drive you around [Thursday 17th April 2014]
Driverless cars are coming, sometime and maybe. Some of us, at least some of the time, still enjoy driving. But even if you never let the car drive itself when you're in it, even if you always drive to pick people up and drop them off, there are plenty of reasons why you might
let the car drive itself when you're not in it. The additional capabilities this gives the car may change the way we use cars at least as much as when we're in them.
A lot of the driving you do in your car is ancillary to owning a car, rather than being to service the things you want. If the car can drive itself around, some of that goes away. And there's some routine stuff it can do too. Consider these possibilities:
- You drive to the city centre to go shopping. But you don't drive around looking for parking, you just drive to where you want to go, get out, and say "go find a parking space" and the car obeys. When you need it back, you can summon it with your phone.
- The car is due a service. You just go to work as usual, but when you get there you just get out at the office and send the car off to the dealer. Once it's done, the car comes back and parks in the office lot.
- Your daughter phones you from school. She's forgotten her sports clothes, which she needs for third period. You find her sports bag and put it in the trunk of the car. You send it off to her school. When it gets there it parks in the school lot and messages her; at the end of the next period
she comes out and gets the bag from the car (which unlocks only for her).
- You paid for that car that's sitting idle in your garage right now. If you know you won't need it for the rest of the day, if it's self-driving you can rent it out via a car-share site for a few hours to someone else. It'll deliver itself to them when they've booked it, and when they're done
it'll return and park back at your house.
- The car is electric, but your office (mall, cinema, apartment complex) doesn't have enough inductive chargers for every electric car. You turn over (limited) control to the building's valet-manager system, which shuffles all the cars around over their stay, making sure each gets enough charge
to get the driver home.
This last part is maybe the best part. Why does your office, or your apartment building, even have parking next to it? With self-driving cars, it doesn't need to - it can contract parking from some parking lot blocks, even miles away. And valet parking (which is what happens when all the cars in
the lot are self-driving, and are controlled by the lot's valet manage system) can manage where every car is kept. With cars parked millimetres apart (no need to open the doors) bumper to bumper, it can manage double or triple the density of a normal lot. You tell it when when you'll need it, and
the system can make sure the car is shuffled around when it's time. If you have a genuine emergency (which means you can't wait five minutes for an emergency shuffle to occur) the lot will send a taxi.
With self-driving cars, particularly electric ones, the future may spell bad news for parking attendants, taxi drivers, and filling station cashiers.
Adapted from my reddit post of yesterday.
Blog: The pointless Pono [Monday 17th March 2014]
Neil Young (yes, him) is backing a Kickstarter for a new high-definition portable media player,
Pono. It's daft.
Pono promises high quality, high definition digital portable music. CD-DA isn't a perfect format, and munged through mp3 codecs it's a bit worse, with data compression, loudness, range compression, and simply there (usually) being only two channels. In an ideal listening environment, with decent
speakers and a quiet room, this might possibly matter. But in a portable environment it just doesn't.
The track record of better-than-CD-quality digital audio isn't a good one anyway. HDCD, SACD, and DVD-A never made much of a dent. In part people just don't care enough (perhaps they're ignorant of the wonders they're missing, perhaps not), and in part copyright holders are reluctant to put such
a high-quality stream in their customers' hands (knowing how readily media DRM schemes have been cracked). Perhaps it's time for another crack at getting a high quality digital music standard off the ground. Perhaps iTunes and SoundCloud and Facebook have altered the music marketplace enough that
there's room to market better product right to the consumer. A coalition of musicians, technologists, and business people maybe can establish a new format, one that can be adopted across a range of digital devices and can displace mp3 (which is, I'll happily admit, rather long in the tooth).
But portable media is a dumb space in which to do it. And building your own media player is dumberer. People listen to portable players when they're in entirely sub-optimal listening environments. They're on the train, in the back of the car, they're in the gym or they're walking or their
running down the road. There's traffic noise, wind and rain, other people's noises, and the hundred squeaks and groans of the city. And they're listening on earbuds or running headphones or flimsy Beats headphones. The human auditory system is great at picking out one sound source from the miasma,
but it can only do so for comprehension not for quality too. High quality audio in all these enviroments is wasted - it's lost in the noise.
When I started running, I had a hand-me-down Diamond Rio PMP300. It came with only 32MB of internal storage - that's barely enough for a single album encoded at a modest compression level. So I broke out Sound eXchange and reduced my music to the poorest quality I could manage, and eventually reduced it to mono too. With that done, I could get a half-dozen or so albums on the player, enough that I could get enough variety that each run didn't just follow the
same soundtrack. With skinny running headphones, the wind and the rain, the traffic noise, and the sound of my own puffing and panting, it just didn't matter that the technical qualities of the sound were poor. And now, a decade later, when I have a decent phone that plays high quality mp3s, it
doesn't really sound any different in practice.
So even if people buy Ponos, even if media executives decide to sell them high-definition digitial audio, if they pay (again) for all the music, in the environments most people will be using their Pono, the difference will be, in practice, inaudible.
2013
Blog: The zombie invasion of Glasgow [Friday 25th October 2013]
The introductory zombie scene in the film
World War Z, while set in Philadelphia, was filmed in central Glasgow, around the City Chambers and George Square. I know that part of Glasgow pretty well, but they really did an excellent job of making it look American and
disguising its weegieness. I've pored over the entire scene, and here (mostly shot by shot) is a breakdown of where the shot was taken, with Google Maps links.
For each entry I show the time (into the UK DVD edition of the film, in minutes:seconds), the line of dialog roughly about that time, a description of the streets shown, and a Google Maps link (you might need to rotate the camera in a few of them):
- 04:56 20 questions - Junction of Cochrane St. and Montrose St., looking west up Cochrane St.
(map)
- 05:35 "what is going on?" - Junction of Cochrane St. and John St., looking west up Cochrane St. Emporio Armani visible on the left.
(map)
- 06:26 "you all right?" - Cochrane St., west of Montrose St., looking east down Cochrane St. The Bridal Studio visible in the distance.
(map)
- 07:14 "I want my blanket" - Junction of Cochrane St and South Frederick Street. Statue of scientist Thomas Graham with The Piper behind it.
(map)
- 08:17 "out of the way" - George Street, between North Frederick Street and John Street, looking east down George Street. A sign for US30 over the Ben Franklin Bridge in Philadelphia is present. In
reality we're about 100m north of the garbage truck crash.
(map)
- 08:34 "ahh!" - Helicopter shot over Glasgow City Chambers' central tower looking west over George Square. The camera pans clockwise until we're looking roughly at #5
(map)
- 08:41 "aargh" George Square at North Hannover Street looking east down George Street. The white base of the statue of Gladstone is visible right of frame.
(map)
- 08:44 faces of running people - As #5, but looking west back into George Square. The Tron Church is replaced by a glass skyscraper.
(map)
- 09:22 "seven" - George Square (West George Street) at North Hannover Street, looking westward down George Street. Now the Tron Church is present.
(map)
- 09:49 starting the RV - High shot from #5, showing the north facade of the City Chambers
- 10:05 more running - I'm confused about this one - it may be a computer collage
- 10:06 racing toward bridge - Again as #5, looking east down George Street. But the blue metalwork of the Ben Franklin Bridge is visible
- 10:08 roadblock - On the bridge: woosh, we're on the bridge on the Camden NJ shore, looking west into the Philly.
- 10:13 zombies teeming through George Square - Another helicoper shot, this time over Queen Street looking eastward at the front of the City Chambers. The crashed garbage truck is in the right place.
(map)
- 10:17 helicopter - view from the back of a helicopter, of Philly's Liberty Place
Blog: Changing the Gnome/Unity background in Python [Friday 4th October 2013]
It's easy to change the desktop background from Python, without using an external program.
Here's a basic example for Gnome (including Unity) on Linux:
#!/usr/bin/env python3
from gi.repository import Gio
bg_settings = Gio.Settings.new("org.gnome.desktop.background")
bg_settings.set_string("picture-uri", "file:///tmp/n2.jpg") # you need the full path
# you can also change how the image displays
bg_settings.set_string("picture-options", "centered") # one of: none, spanned, stretched, wallpaper, centered, scaled
You'd think that it would be just as straightforward to do this on KDE4; it was possible with pydcop on KDE3, but I can't find a way of doing on KDE4 with dbus. I've seen some postings which suggest that they're almost at the point of adding support for this.
Blog: File magic for the constituent parts of Linux RAIDs [Saturday 15th June 2013]
Curiously, the
magic(5) for
file(1) on my machine doesn't recognise the format of superblocks which make up a Linux RAID, instead simply reporting them as "data".
This Python2 program dissects the header of a given block and shows some information about it and the RAID volume of which it is a constituent.
#!/usr/bin/python
"""
Linux RAID superblock format detailed at:
https://raid.wiki.kernel.org/index.php/RAID_superblock_formats
"""
import binascii, struct, sys, datetime, os
def check_raid_superblock(f, offset=0):
f.seek(offset) # start of superblock
data = f.read(256) # read superblock
(magic,
major_version,
feature_map,
pad,
set_uuid,
set_name,
ctime,
level,
layout,
size,
chunksize,
raid_disks,
bitmap_offset # note: signed little-endian integer "i" not "I"
) = struct.unpack_from("<4I16s32sQ2IQ2Ii",
data,
0)
print "\n\n-----------------------------"
print "at offset %d magic 0x%08x" % (offset, magic)
if magic != 0xa92b4efc:
print " <unknown>"
return
print " major_version: ", hex(major_version)
print " feature_map: ", hex(feature_map)
print " UUID: ", binascii.hexlify(set_uuid)
print " set_name: ", set_name
ctime_secs = ctime & 0xFFFFFFFFFF # we only care about the seconds, so mask off the microseconds
print " ctime: ", datetime.datetime.fromtimestamp(ctime_secs)
level_names = {
-4: "Multi-Path",
-1: "Linear",
0: "RAID-0 (Striped)",
1: "RAID-1 (Mirrored)",
4: "RAID-4 (Striped with Dedicated Block-Level Parity)",
5: "RAID-5 (Striped with Distributed Parity)",
6: "RAID-6 (Striped with Dual Parity)",
0xa: "RAID-10 (Mirror of stripes)"
}
if level in level_names:
print " level: ", level_names[level]
else:
print " level: ", level, "(unknown)"
layout_names = {
0: "left asymmetric",
1: "right asymmetric",
2: "left symmetric (default)",
3: "right symmetric",
0x01020100: "raid-10 offset2"
}
if layout in layout_names:
print " layout: ", layout_names[layout]
else:
print " layout: ", layout, "(unknown)"
print " used size: ", size/2, "kbytes"
print " chunksize: ", chunksize/2, "kbytes"
print " raid_disks: ", raid_disks
print " bitmap_offset: ", bitmap_offset
if __name__ == "__main__":
if os.geteuid()!=0:
print "warning: you might want to run this as root"
if len(sys.argv) != 2:
print "usage: %s path_to_device" % sys.argv[0]
sys.exit(1)
filehandle = open(sys.argv[1], 'r')
check_raid_superblock(filehandle, 0x0) # at the beginning
check_raid_superblock(filehandle, 0x1000) # 4kbytes from the beginning
and here is additional
magic(5) data to recognise RAID volumes. It's incomplete - I've only been able to test it with RAID volumes I've been able to create myself.
# Linux raid superblocks detailed at:
# https://raid.wiki.kernel.org/index.php/RAID_superblock_formats
0x0 lelong 0xa92b4efc RAID superblock (1.0)
>0x48 lelong 0x0 RAID-0 (Striped)
>0x48 lelong 0x1 RAID-1 (Mirrored)
>0x48 lelong 0x4 RAID-4 (Striped with Dedicated Block-Level Parity)
>0x48 lelong 0x5 RAID-5 (Striped with Distributed Parity)
>0x48 lelong 0x6 RAID-6 (Striped with Dual Parity)
>0x48 lelong 0xffffffff Linear
>0x48 lelong 0xfcffffff Multi-path
>0x48 lelong 0xa RAID-10 (Mirror of stripes)
0x1000 lelong 0xa92b4efc RAID superblock (1.1)
>0x1048 lelong 0x0 RAID-0 (Striped)
>0x1048 lelong 0x1 RAID-1 (Mirrored)
>0x1048 lelong 0x4 RAID-4 (Striped with Dedicated Block-Level Parity)
>0x1048 lelong 0x5 RAID-5 (Striped with Distributed Parity)
>0x1048 lelong 0x6 RAID-6 (Striped with Dual Parity)
>0x1048 lelong 0xffffffff Linear
>0x1048 lelong 0xfcffffff Multi-path
>0x1048 lelong 0xa RAID-10 (Mirror of stripes)
Blog: A complete logical system based on material implication [Friday 26th April 2013]
A few days ago I watched R. Stanley Williams' presentation
Finding the Missing Memristor, which talks about building digital systems from
memristor, a novel basic
electronic component. Near the end, Williams talks about a memristor lending itself to easily building a
material implication logic element (at
38 minutes into the
presentation). He mentions, but doesn't go into detail, that with only this primitive, and a predefined "False", one can build the full set of
basic logic elements.
I'd long been familiar with the idea that one could do so from NAND gates (building a complete NAND logic) and similarly from NOR
gates (producing a complete NOR logic). Indeed, every current digital electronic system is build from one of these two schemes. But I didn't know about the completeness of implies-logic, and I'll confess to being a bit intimidated by
Principia Mathematica. So I figured I'd work through building the system myself. Here goes.
We start with the material implication operator →, which has the following truth table:
More of interest to logicians than electronic engineers, note that x → x is always True, for either value of x. So, logically speaking, it's fair to say that material implication gives rise to True (that having True a priori isn't necessary); the same isn't true for False. Someone
building an actual digital circuit with memristors isn't really going to care, because a logical True and False (presumably a high and low voltage feed) are always readily available anyway. I don't know enough about the actual implementation of a memristor → gate to know whether, if you just
tied the two input lines together (and not to an input line from elsewhere in the circuit), you'd actually get a consistent True level out of it (but I'm guessing you wouldn't).
With that, we can build an OR gate (denoted as ∨)
p ∨ q is (p → q) → q
And negation, an inverter gate (denoted as ¬):
¬p is p → F
With not and negation we can build a logical NOR (denoted with Peirce's arrow ↓)
p ↓ q is ¬(p ∨ q)
so
p ↓ q is ((p → q) → q) → F
...and from that point we could follow the pattern of NOR logic and build the rest of the system. Just for completeness, we can build and (∧) and nand (↑)
p ∧ q is (¬p) → (¬q)
p ↑ q is ¬(p ∧ q)
Finally we can construct xnor (logical equality, denoted =) and exclusive or (xor, denoted ⊕)
p = q is (p ∧ q) ∨ (p ↓ q)
and
p ⊕ q is ¬=
Blog: Cyberwar on /North Korea/? [Saturday 20th April 2013]
Apparently Anonymous, that vaguely extant hacktivist group that lazy journalists like to write about when they're Googling for news rather than going out and doing their actual job, has threatened to declare "cyberwar" on the fancifully named Democratic People's Republic of Korea [link].
Cyberwar on North Korea? That seems as likely to be effective as declaring cyberwar on House Lannister.
Blog: To cure you they must kill you [Wednesday 3rd April 2013]
I spent a little time fixing someone's Windows system. Because, you know, Windows is easy to use. It didn't have a virus; it just had an inexplicable amount of anti-virus. It seems that the anti-virus program's chief strategy to fight virus infection is to just fill up all the
memory and use all the CPU cycles itself, so there's no headroom left for the viruses to get in. It's a bit like trying to cure yourself of a blood disease by injecting your veins with bath sealant.
Blog: Is Valve's destiny THREE? [Thursday 10th January 2013]
Here's a weird little pet theory for you. Consider our friends over at Valve Software, makers of the excellent
Half Life 2,
Portal 2,
Left4Dead 2,
Dota 2, and
Team Fortress 2. That's a whole lot of 2s. Of these,
Half Life 2 is the
oldest, and the next chapter of the series the most painfully overdue. So where do all these unrelated games go from here? Well, to
THREE, obviously.
Given Valve's fondness for being silent until they're sure they're in a good position to deliver, it's easy to go from casual imputation to wild fantasy. So, without any evidence at all, here's my wild guess about the future of each of Valve's core game titles:
- All these titles exist in the same fictional universe ("Valviverse?"). Half Life and Portal are already (slightly) interrelated, and it's not hard to figure out how to incorporate the anarchy of Left4Dead's Green Flu
zombie pandemic into Half Life's Seven Hour War, as perhaps a Combine bio-weapon meant to soften up resistance and thin out the human population before and after their primary military operation. I'll admit that it's harder to work
the cartoonish mayhem of Team Fortress and the fantastical lunacy of Dota, as they're not really very compatible with the gritty world of Half Life. The usual scriptwriter follies are still available - alternate dimensions, distant past or future, VR simulation, and (my
favourite) "you broke reality with your damn manchine".
- So let's call all these games THREE - but I'm not suggesting that Value consolidate these different franchises (each a distinct genre, with different fanbases) into a single game. They obviously need each individual game to remain a distinct product, but tying them together into a single
milieu makes each work for the other.
- The story unfolds through each episode, and through subsequent DLC for each.
Why would Valve do this, when they're already swimming in money, and when each franchise is individually healthy (if we consider Half Life's lengthy state of hybernative naptosis to be healthy? Because Valve need to sell as many of their forthcoming Steam Box PC/console/TV hybrid thing as possible. And rather than simply boast a bunch of sequels as launch content, weaving the whole thing into a major event can
only enhance the press coverage and gamer hunger for the thing.
If they do this, Valve's track record suggests they'll tease it somehow, perhaps by an ARG, or by some subtle under-the-wire DLC. With everything already updated on Steam for technical reasons, it'd be easy for them to alter some
noticeboards or leave the odd corpse from one game in another.
Now, that's thinking with portals.
2012
Blog: Aliens vs. Thanksgiving [Tuesday 20th November 2012]
It's at this time of year that millions of college-age Americans return to the family home and to their childhood place in the family structure. Some can decide whether to sit at the kids' table or the adults'. If they choose the adult table, they'll hear an hour-long lecture about how Barack
Obama is an evil alien who is out to destroy America; if they sit at the kid table, they'll hear an hour long lecture about how Megatron is an evil alien who is out to destroy America.
Does this mean that Barack Obama is really Megatron?
Blog: Great Scottish Run 2012 [Tuesday 4th September 2012]
As with last year, I did the Great Scottish Run (a half marathon around Glasgow) on Sunday. This time I did it in 2:12:15, three minutes slower than last year.
Although it was a little cooler than last year, and I was better hydrated and probably better prepared, I still ran a bit slower - I really don't know why. Running past someone on Ballater Street who was being treated by paramedics, and was clearly having a serious problem, surely made me decide to
slow down a bit. Plus being a year older and 3kg heavier than last year didn't help.
This year the winning time was 1:03:14, with the mean finishing time 2:02:54 and the most popular finishing time 1:57:44. The graph showing the distribution of runners (new improved with labels) is very much like last year's distribution:
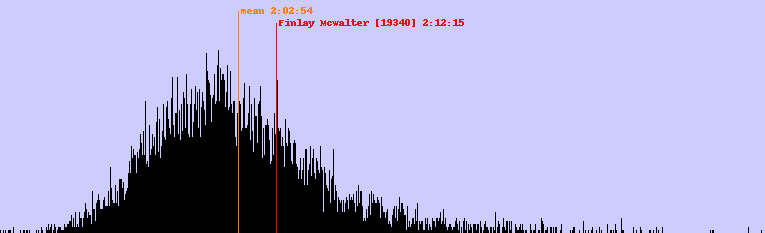
The Python2 code to generate the graph is below. It'll probably need to be tweaked for subsequent years, as they're not very consistent about the CSV data dump.
#!/usr/bin/env python2
# config parameters
# a dictionary giving the runner number and the colour we're going to draw their line as - their
# name is extracted from the CSV ffile.
runners_to_show = { '19340': {"colour": 'red'},
}
RESOLUTION=15 # how many seconds correspond with each horizontal pixel
VSCALE=3 # vertical multiplier
# ##############################################################
import csv, sys, Image, ImageDraw
# overall stats
mintime = 10000
maxtime = 0
count = 0
totaltime = 0
# gender totals
boycount = 0
boytotal = 0
girlcount = 0
girltotal = 0
# the census has one bucket for each "slice"
census = [0]*(RESOLUTION*1000)
most_popular_time = 0
most_popular_count = 0
def parsetime(t):
"convert an h:m:s time into a number of seconds"
h,m,s = t.split(':')
return int(h)*3600 + int(m)*60 + int(s)
def unparsetime(t):
"convert a number of seconds into a hh:mm:ss string"
t = int(t)
hours = t/(60*60)
t -= (hours*60*60)
mins = t/60
t -=(mins*60)
return '%d:%02d:%02d' % (hours,mins,t)
try:
infile = open ('2012GSRHalfMarathon.csv','r')
except IOError:
print "error opening input file"
sys.exit(1)
reader = csv.reader(infile)
for row in reader:
place, number, time, forename, surname, gender, age, club, split1, split2, split3, filler = row
# do some stats
sectime = parsetime(time) # time in seconds
if sectime < mintime: mintime = sectime
if sectime > maxtime: maxtime = sectime
count += 1
totaltime += sectime
if gender == 'M':
boycount += 1
boytotal += sectime
else:
girlcount += 1
girltotal += sectime
# is this row the entry for a runner we're particularly interested in
for k in runners_to_show:
if k == number:
runners_to_show[k]['name'] = forename+" "+surname
runners_to_show[k]['time'] = time
runners_to_show[k]['sectime'] = sectime
print 'found runner', k, runners_to_show[k]
# keep a census for each possible finishing time
index=sectime/RESOLUTION
census[index] += 1
if census[index]> most_popular_count:
most_popular_count = census[index]
most_popular_time = sectime
# show the results of our pass through the data
print 'mintime', mintime, unparsetime(mintime)
print 'maxtime', maxtime, unparsetime(maxtime)
meantime = totaltime/float(count)
print 'meantime', meantime, unparsetime(meantime)
print 'most popular finishing time: %s (%d people)' % (unparsetime(most_popular_time),
most_popular_count)
# render an image, with a histogram for the census
minbucket = mintime/RESOLUTION # the leftmost bucket
image_width = (maxtime-mintime)/RESOLUTION
image_height = (most_popular_count*VSCALE) + 50 # 50 is padding at the top
im = Image.new('RGB', (image_width, image_height), '#ccf')
draw = ImageDraw.Draw(im)
# draw the overall histogram
for x in xrange(image_width):
draw.line([(x,image_height),
(x,image_height- (VSCALE*census[x+minbucket]))],
"black")
texttop = 5
# draw mean line
x = (meantime-mintime)/RESOLUTION
draw.line([(x,image_height),
(x,11)],
'#FF7F00')
draw.text((x+3,texttop),
"mean " + unparsetime(meantime),
'#FF7F00')
texttop += 12
# draw each of the specified runners' times
for racenum,data in runners_to_show.iteritems():
x = (data['sectime']-mintime)/RESOLUTION
draw.line([(x, image_height),
(x, texttop+6)],
data['colour'])
draw.text((x+3,texttop), "%s [%s] %s" %(data['name'],
racenum,
data['time']),
data['colour'])
texttop += 12
del draw
im.save('graph2.png')
edit: I later discovered that the runner who was being treated, Aubrey Smith, died. There's a weird fraternity between runners, and when one of us falls we all hurt.
Blog: Under Google's bonnet [Tuesday 8th May 2012]
I've just noticed that in Google Chrome's settings screen, the section with all the technical stuff is called "Under the Bonnet" in the en-uk version, and "Under the Hood" in the en-us. It's a little thing, and in itself it doesn't really matter (I doubt many UK users wouldn't
know what "under the hood" means), but it does show that someone is paying attention to the details, which has a positive halo effect for one's perception of the rest of the product.
Blog: ipod nano replacement [Saturday 5th May 2012]
Back when it first came out in 2005, I bought one of the first generation of Apple iPod nanos. It's been a few years since I retired it, replacing it with an iPod Touch and then an Android phone - but I'm pretty good about storing old things like this properly, with all the
necessary equipment and in good order. It seems Apple are worried these old things pose a fire risk, so they're replacing them.
Apple's page about the replacement program calls it a "safety risk" without providing much detail; Wikipedia's article mentions a few overheating events (but really not
a lot). Still, Apple are clearly worried about their liabilities. So they took back the old one (a black 2GB model) and they've sent a new 8GB silver one.
It's slightly strange to get an Apple product like this. There's none of the usual Apple "unboxing" experience, because there's no box at all. The Nano came in a generic shipping box (one downright Brobdingnagian when compared with the tiny size of the player). No manual, no cable, no software,
just the tiny Nano with a serial number sticker.
I'm surprisingly sentimental about technology. I still have every mobile phone I've ever owned (though I've given one to a relative) and, until this, every mp3 player too, right back to a Diamond Rio PMP300. If it hadn't been for the fire
risk, which really prevents me from lending the old thing to someone else, I'd probably have kept it.
Still, the new Nano is an impressive little thing. It weighs very little (it's almost light enough that one could keep it only on the cable), the built-in clip is a nice idea, and the touchscreen works nicely. The build-in pedometer doesn't compare very well with a decent Oregon Scientific one,
however - it seems to be rather arbitrary and unresponsive.
2011
Blog: In praise of the Shire calendar [Tuesday 20th December 2011]
It's almost the festive season, and following that we'll be changing the calendars to another year. The current Gregorian calendar that we use is a mad palimpsest of the last two thousand years of calendar craziness. In combination with the incomfortable facts about the
Earth's orbit (which don't lend themselves to any neat symetrical solution), we're left with 14 different calendar configurations and an odd hodge-podge of months.
These Johns
Hopkins researchers propose a simpler system, but it has a "leap week" ever so often - so it's hardly a rational improvement. But this problem was solved decades ago, by the unlikeliest of inventors.
The most elegant solution to the calendar I've seen is JRR Tolkien's (yes, him) Shire Calendar:
- It's fully conformant with the astronomical realities (no magical even-divisions or date fudging necessary).
- There are still 12 months (so no weird decimal months, no 34th of Thermidor bollocks). You can stick with the familiar month names (rather than Tolkien's Hobbity ones).
- Each month is 30 days long (simplifying accounting, pay calculations, holiday accrual etc.). No pointless variation, no mnemonics.
- Year on year, a given month always begins with the same day of the week. Even for leap years. So if you were born on a Tuesday, your birthday will always be Tuesday.
- The clever part (which allows all the other stuff to happen) is there is a winter festival holiday (2 days) and a summer festival holiday (3 days normally, 4 in leap years). These aren't week days and aren't in a month - they're special. So e.g. Christmas doesn't change between sometimes being
in the weekend, or adjacent to the weekend, or midweek - Christmas is always in the same place. I know I always get disoriented around Christmas - Christmas already seems like a special day which doesn't resemble a Thursday or a Sunday or whatever - the Shire Calendar is just a realistic expression
that it's not a weekday, and that it shouldn't be regarded as one. And the first day back at work after Christmas is always a Monday.
- The winter and summer festivals are pretty consonant with common practice in many countries anyway. Move Christmas into the yule holiday (Jesus wasn't born in December anyway, so it's no less Biblically correct than current practice). Many countries have a midsummer festival or summer bank
holiday and US independence day can be celebrated then.
- You only need one printed calendar (not the 14 different types we currently need) - you just score off the leap year or not.
- Its easy to fix the locations of other festivals, like Thanksgiving, and then you get a perfectly consistent gap between e.g. Thanksgiving and Christmas
- From a software perspective it's a wash - 2 more mini-months need to be handled, but less bother with differently lengthed months and much easier day-of-the-week calculations.
Adapted from my Slashdot post here
Blog: What men and women want from movies [Thursday 20th October 2011]
What women want from a movie:
- in the beginning the people meet
- in the middle they argue
- in the end they get together
What men want from a movie:
- in the beginning the people meet
- in the middle they get together
- in the end they get eaten by dinosaurs
Unless film makers do something cheesy like a
fake ending (which women are somehow tricked into missing), these two rubrics aren't compatible.
Blog: This human form I now repent [Tuesday 20th September 2011]
I ran my first half marathon this past Sunday, the
Great Scottish Run in Glasgow.
I've never competitively run further than the 12km Bay to Breakers, but I'd prepared pretty thoroughly. On the day the various suspect joints that I feared might let me down all performed perfectly, but I messed up a bit on the hydration
plan, and an uncharacteristically hot Glasgow left me rather seriously dehydrated by the end (but that's no excuse, particularly for the 5533 people who finished faster than I). I did it in 2 hours 9 minutes, which was about what I estimated beforehand, but I'd have done a deal better had I drunk
properly beforehand.
I'm especially grateful to the kind folks from the Glasgow Sikh community, who set up their own unofficial water station (amid an inexplicable five-mile gap between official water stations) and who had some Kärcher pressure washers to douse the overheated runners.
I've been dehydrated running before, but never this badly, so I was in a pretty feeble condition afterwards. It's unpleasant.
A Google Map showing a GPS trace of the route on Google Maps is here (it's weirdly punctuated in the latter section, I guess due to the water spraying).
The race organisers have placed a CSV of all the half-marathon finishers (with splits) in a machine-parsable file here, so I've had some fun grinding through them (it's not like I'll be walking anywhere today).
Of the 8482 runners who finished (they don't give statistics for non-finishers) 5187 (61%) were men and 3295 women. The male winner was Kenyan runner Joseph Birech in an eye-watering 01:01:26, and the
female winner was fellow Kenyan Flomena Chepchirchir in 01:09:26 (beating, I believe, her PB).
The mean time for the whole field was 02:03:32, with a peak of people finishing around 01:57 (what, did you guys hold hands?). For men only the mean time was 01:57:20, for women only the mean time was 02:13:17
My own time put me 6 minutes slower than the overall mean, and 12 minutes slower than the male mean. A graph showing the distribution of runners' finishing times is below - the overall mean is the green line, I'm the puffy and out-of-breath red one.
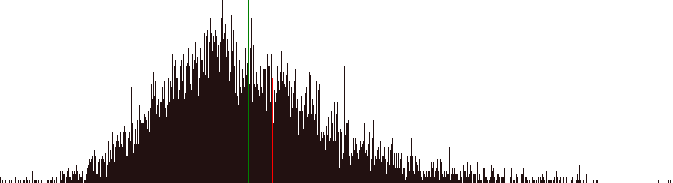
In the last 6k I overtook 176 people but 203 people overtook me (so that's a net 27 people who'd taken better care to drink properly). Of these runner #13180, Angus Denham, went from being 5 minutes behind me to finishing nearly 3 minutes ahead. Perhaps Angus is really Batman.
Of the whole race, the most impressive kick (the fastest last section in relation to their first 15k) was by runner #19069, Gary Clelland (splits 00:34:05, 01:20:14, 02:04:03) who seems to have had a horrible middle race, but recovered to do the last 6k in 31 minutes.
Blog: It's time to tune the fire alarms [Tuesday 20th September 2011]
I was up several times last night, and slept very badly, because
one of my smoke alarms was complaining that its battery was dying, and so beeping intermittently. Figuring out
which isn't an easy problem (at 3am nothing is an easy problem) but one that could be
made easier.
BEEP!
There are two alarms in my house. They're mains wired with a 9V battery backup, and when that battery starts to fail (it seems when it gets below about 7.7V) the alarm beeps once, very briefly. The beep is frustratingly irregular, and there's at least several minutes between beeps. There's no
light or other visual indicator on the alarm which is failing. And (as anyone who has heart the siren of an emergency vehicle echoing around the buildings in a densely built up city) it's difficult to spacially locate a high-frequency tone that's echoing off hard surfaces.
BEEP!
The alarms are mounted up high, on the ceiling, they're difficult to remove (push a little tab with a knife while turning the whole thing anticlockwise), and the screwthread is a bit overpainted. There's residual capacitance in an alarm, so even if you remove its battery and disconnect it from
the ceiling supply, it will still muster the energy to beep a few more times. I think I know which alarm it is, so I take it down, open it, remove its battery, find a spare 9V, replace that, restore the detector to the ceiling, and go back to bed. Mission accomplished. All is peace and quiet.
Sleep.
BEEP!
Darn - I must have changed the wrong one. Find another 9V battery. Remove the second alarm (which is much more intransigent than the first), fix it, replace it. Now they're both done. Sleep.
BEEP!
It's 3:30 and this is impossible. Can I have put a bad replacement into one of them - but which? I take them both down, and find the Fluke DVM. How are "normal" people supposed to solve this kind of problem in the early hours of the morning (where "normal" people don't have a stash of 9V
batteries and a digital multimeter) ? I test both "good" batteries - they're showing slightly more than 9V. The two "bad" ones aren't much different - one is 8.3V and the other 8.7V. I don't have any more batteries to try, it's late and I need to work tomorrow, and there's obviously nowhere open
that will sell me two 9V batteries at 4am. I can't think. I disconnect both batteries and leave both alarms on the desk. I pile clothes on the alarms to deaden the sound (knowing they'll beep for a while until their caps have discharged), close all the intervening doors, and go to sleep.
BEEP! BEEP! BEEP! BEEP! all ... night ... long ...
In the morning, when I feel only a little bit more awake, I still can't figure out the problem. There's still a periodic beep, and it can't be either of the alarms. As I stumble around, another BEEP! And then I find it - a third alarm, this time a carbon monoxide detector, hiding in the
cupboard beside the heating system. Its battery is 7.2V, and given the 8.7V one it's happy.
It's stuff like this that makes well-meaning people throw their smoke alarms away, or at least permanently neglect to put batteries in them. I understand why it has to beep, and why it can't flash a permanent light to say it's in trouble (they're trying to maximise the time of protection I get,
even at the expense of my sleep). It's a very simple and cost-optimised device, so it's difficult to think of a sensible way for it to communicate. All it can do is beep.
But do all three detectors have to beep the same? The beep function is a simple piezo electric sounder driven by a simple frequency generator (I guess an XTAL) and gated by a transistor. So:
- At the very least it should be straightforward to substitute a different frequency generator for different detectors in a set. A set of detectors might have one at C, one at G, and one at E♭. A detector bought singly could have a pair DIP switch to set one of four codes.
- If a throwaway novelty greetings card can play a tune, is it really too much cost to have the smoke detector tap out its ID code (maybe two digits, each 1-6 beeps, with a gap between them)? The code can be cooked into the detector, with a little screenprinted decal on the side showing its
code.
- With only a little more cost, make each detector play two notes concurrently with a fixed interval. Right now I'd hope for a nice consonant interval like a major 3rd or a perfect 5th, but I suppose smoke alarms are supposed to sound horrible. So one detector could play a tritone, one a
major seventh, and another a minor second (all with different tonics). Those all sound nasty and urgent, but they also sound different.
Blog: What is a VPN exactly? [Thursday 1st September 2011]
A few days ago, over on Reddit, someone asked "What is a VPN exactly". Wikipedia has a
pretty good, but very technical article on the subject. Instead I
answered with along (and perhaps a tad tortured) analogy. It's reproduced below.
Let me try this analogy out on you (let me know if it makes sense):
- Imagine first that you work for a medium sized company - 300 people in one building. All day long you process paperwork, which you then need to send to other people in the company. Rather than spending all day walking about, you put your intra-office mail into an outbox near your office. A few
times a day a guy with a cart comes round. He delivers mail to you, and takes all the outgoing stuff. The outgoing stuff gets sorted in the mailroom and goes onto the next cart. The address you write on the envelope is a local one; it just says the person's name and their department (not the
company name, or street address, or city, state, or country). That's like a local-area-network.
- You also have to deal with people in other companies. So when you send them stuff, you put on a full public street address, with city and country and postal code. When your mail guy sees that, he puts it in a pile for the public post office. The postman picks it up, and it gurgles through the
public postal system until it gets to the recipient's company. There another postal guy sorts it (with all that company's intra-office mail) and delivers it to the final person. That's like the Internet.
- But now imagine your company expands. They open a new office on the other side of the country, and reorganise so some departments move there, while some stay at the current location. The guy with the mail cart can't walk over there to deliver stuff, so it'll have to go by the public mail. You
could keep a list of which department is where, and if you wanted to mail someone in one of the remote departments you'd treat them as if they were an external person, and write their full address. But that's complicated and inefficient, and lots of people in your building will be sending stuff to
people in the remote building, just like you. So the company says you don't have to change anything. You put the same name and department code you always did. The mail room people know who has moved, and so they build up a pile for stuff going to the remote site. And for efficiency (and often for
security) they bundle these up into one big mailbag, and mail that across the country. It goes on various vans a trucks and planes, sharing them with mail for other companies to other people, and being handled by all kinds of mail workers who're unrelated to your company. At the far end the company
mail people open the bag and treat all the mail inside it just the same as if it was local. So, to both sender and receiver it looks like it's local mail, even though it's gone through the public mail system to get to you. That's like a virtual private network - it appears like the private local
network, but (if you actually follow packages around, how they actually get from A to B) it's over a public mail system.
- That basic VPN, above, is okay, but it has security concerns. If your company mail deals with confidential stuff like sensitive financial documents or secret stuff like stealth fighter components, you'd be worried about all those normal mail workers handling your mail. They could open that big
mailbag and steal the contents, or copy them, or even change them. The people who work at your company have been security checked, but you don't know anything about those regular people in the mail system, and you don't trust them. So your company uses a super-strong kevlar-weave mailbag with a
fancy padlock on it. The mailrooms in both branches of your company have the keys to the padlocks, but the people who work for the public post office don't. So that way, hopefully, your mail won't get read or stolen in transit. With that security done, you can be confident of sending stuff from one
office to the other - it's as safe (if the bag and lock are good) as if you just posted it to someone in another department in the same building. That's an encrypted VPN (really all VPNs are encrypted, so you always have confidence).
- For you working from home, things are much the same, just on a small scale. People post stuff to you as if you were in the office, and the mail people know where to send it, and wrap it in a secure bag.
In all this analogy (I hope it wasn't too tortured) all the mail people, both in your company in in the public postal system, are network routers. The VPN works because your company has told its routers how to do the special work of wrapping up remote intra-company mail in secure wrappers and
readdressing them, and then unwrapping them at the far end. So to partake of a VPN both ends need to have special VPN software, that alters the normal routing scheme to do this. That usually entails your company sites having routers (or servers) that accept requests in the PPTP protocol (that's the
secure bag) and does authentication with CHAP or EAP or the like (that's the padlock). And you need to have similar software on your computer too. With that set up, and with you logged in to the VPN properly, it appears as if your computer is plugged into the network as if you were back at the
office, even though you're in a webcafe in Nepal. Depending on what the VPN is programmed to allow through, you can access network shares or intranet sites, you can even print on a printer back in the office. The VPN hides the complexity and insecurity of the public network (although you probably
notice things are slower).
So yes, a VPN is just what you need. To set one up will need the help of whoever manages your company network. They may choose to configure VPN functionality on existing hardware, or to install additional hardware or software. They'll have to worry about opening a special connection in the
firewall so VPN clients can phone in to establish their sessions, and they'll have to think about how to manage who gets to login and how to authenticate they are who they say they are.
I probably should mave mentioned Peter Deutsch's
8 fallacies of distributed computing, which all apply in this case and which all would apply with a physical mail system (of sufficient complexity) too.
Blog: Monitoring dd progress [Wednesday 20th July 2011]
dd is one of a unix administrator's best friends - it's great for making block-level backups, secure erasure of confidential data, moving a filesystem, or generating test data. But it's pretty common to set
it off on a large job and come back later and have no clue about how much progress it's made. John Newbigin's
dd for Windows has a non-standard
--progress option, but with the standard one it's not so straightforward.
The GNU dd has a nice feature whereby it prints its progress if you send it a SIGUSR1 (e.g. kill -USR1 1234). But if the dd process is wrapped in other processes, or isn't attached to a console, then you can't easily get this information.
Say we're running dd if=/dev/zero of=/dev/sdc
How do we figure out how far it's gone?
To the rescue comes the admin's other best friend, Vic Abell's invaluable lsof
lsof -c dd | grep sdc
reports
dd 2662 root 1w BLK 8,32 0x187e768000 5482 /dev/sdc
The key part of that is 0x187e768000, which is the offset it's reached, in hexadecimal.
To simplify checking that, the following quick and dirty Python script (which takes the filename or device to search for as its only argument) will report the offset field in the lsof output, handily converted to Mb and Gb.
#!/usr/bin/python
import subprocess,sys
if len(sys.argv) !=2:
print 'usage:\n %s <output file or device>' % sys.argv[0]
sys.exit(1)
r = subprocess.check_output('lsof -c dd | grep %s' % sys.argv[1], shell=True)
val = r.split()[6]
if val.startswith('0x'):
base=16
else:
base=10
v2 = int(val,base)
print '%d Mb (%d Gb)' % (v2/1024**2, v2/1024**3)
So if the python script is called dd_progress.py and we run dd_process.py sdc the output will be:
100327 Mb (97 Gb)
Some nice additions: dd can hog the IO bandwidth if given reign, so run it with ionice dd ... so you can still work on the same machine. Rather than continually run dd_progress.py by hand, one can leave it running periodically in another window like this:
watch dd_progress.py sdc
Blog: Games are not realistic (no, really) [Thursday 2nd June 2011]
You really don't
want realistic games, just not stupid ones
If history was like computer games, the Second World War would have ended when Franklin Roosevelt and Winston Churchill sneaked into Hitler's castle (through a ventilation duct) and repeatedly shot a small glowing area of Hitler's neck with their rocket launchers and bakelite laser guns.
If computer games were like history, a game of Starcraft would consist of years of committee meetings about increasing bauxite production and improving the machine tool lubricating oil supply chain, and you'd get an email once a week giving you a statistical breakdown of the friendly and enemy
units destroyed in the conflict.
Blog: Apple and the tiny SIM [Thursday 19th May 2011]
In
this Reuters story, Apple proposes smaller, thinner
SIM cards. But does anyone need a smaller mobile
phone than we already have?
In the short run they're looking at making a phone that's a few mm thinner than the current ones. But in the longer term they're thinking beyond what we currently call a "phone". They're looking at very small form factor devices which keep their data in the cloud, are configured by another
(arbitrary) device which talks to the same cloud, and which make either sporadic or continual data connections with whatever available networks they find, to keep up to date. Imagine very small devices (wristwatches, eyeglasses, earplugs) with 802.11/UMTS/WiMAX radios (which use a mini-sim to
identify themselves to whichever network they encounter). And they're thinking about these things as universal identifiers and payment tokens.
Right now you go running with an iPod. Instead you'll have a iPlug, a pair of little in-ear headphones, but with no cable and nothing strapped to your arm. You set up your music program on a tablet, and it seamlessly syncs. You run further than you'd expected, so the iPlug connects to the
network and downloads more music. Miles from home your knee gives out. You touch the iPlug and say "taxi". A taxi comes (sent by Apple to the location the iPlug knew; Apple gets a dollar from the taxi fare, which you pay using the iPlug).
You have a iSim unit in your iWatch. You're thirsty, so you touch the watch and say "coffee shop". The watch face shows an arrow to a nearby one, and the distance, and walks you there. Apple gets a dollar. You buy a drink with the iSIM as a payment token (Apple gets 30 cents) and sit down at a
table. The table's surface is an active display; it talks to your iWatch and opens a connection to your account in the iCloud. Your personal news appears, your emails, your documents. You do some work, browse some stuff, and when you're done you stand up and the table blinks off. Things will be as
you left them when you next peer with an active display - at home, in the car, on the train, at the office, on the beach.
All of this stuff has been done, in various disconnected ways, already. You can pay for stuff with your phone, in some places. Most Europeans (well, Brits at least) have smart cards in their credit cards. You could hotdesk 10 years ago with a SunRay (kinda). You can unlock doors with a Dallas iButton token. Having super-cheap super-light totally ubiquitous networking makes the whole thing join up into a compelling, powerful, system.
You'll never be alone again.
Adapted from my Slashdot posting here. Several posters astutely point out that tiny devices have tiny batteries and so short lives. For a device that's mostly connected to local (low-power) connections, that isn't
configured to receive calls (which means it doesn't turn the radio on every few seconds to check for messages or calls) and which you habitually dock to recharge every day, this isn't an unreasonable ask.
Blog: Guitar effects on Ubuntu [Wednesday 18th May 2011]
Rakarrack is a brilliant guitar effects processing system for Linux, which provides an impressive range of effects including chorus, flanger, distortion, echo and a bunch of stuff I don't begin to understand.
To use it you need to plug your guitar into your Linux PC. It's possible to do this with a direct connection but the signal will be weak and noisy. It's much better to use a proper boosted instrument connection - there are
many of these, but this posting talks about setting things up with the inexpensive Behringer UGC102 USB device. Various online merchants sell this for around £30.
Once you've got that, the following guide lets you get Rakarrack working in Linux. I've tested these instructions in Ubuntu 11.04 (and it mostly works the same in earlier Ubuntu releases); hopefully things should be much the same in a similar modern Linux like Fedora.
- In Ubuntu Software Centre (or Synaptic, or with
apt-get) install the package rakarrack (which will entail you enabling the "universe" repository, if you haven't done so already). By installing rakarrack you also bring in its dependencies, including JACK audio system and its associated utilities. - Save the following script (say to
rak.sh) and make sure that script is executable.
#!/bin/bash
# The following assumes that the Behringer UGC102 is ALSA device #1
# if it isn't, run aplay -l to see what it is
jackd -R -dalsa -D -Chw:1,0 -n3 &
sleep 1
rakarrack &
sleep 1
# mono Behringer inputs to rakarrack stereo input
jack_connect system:capture_1 rakarrack:in_1
jack_connect system:capture_1 rakarrack:in_2
# rakarrack stereo output to both main outputs
jack_connect rakarrack:out_1 system:playback_1
jack_connect rakarrack:out_2 system:playback_2
# wait for rakarrack to be closed
wait %2
# kill JACKd to tidy up
killall jackd
- Plug the Behringer device into a USB port and a guitar into it.
- In
Terminal run aplay -l which will list the audio devices that ALSA can see. A typical report will look something like this:
**** List of PLAYBACK Hardware Devices ****
card 0: Intel [HDA Intel], device 0: ALC883 Analog [ALC883 Analog]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 0: Intel [HDA Intel], device 1: ALC883 Digital [ALC883 Digital]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 1: default [USB Audio CODEC ], device 0: USB Audio [USB Audio]
Subdevices: 1/1
Subdevice #0: subdevice #0 <
In this case "card 1" is the Behringer device (it may vary on your system). 
- If the device is reported as being different from "card 1", change the
1 in hw:1,0 in the script to the appropriate number. - Run the script.
In some configurations, PulseAudio has exclusive ownership of the alsa device, and so jackd can't run. In that case, prepend pasuspender -- to the start of the jackd line in the script. - Rakarrack will appear. You will need to turn on the effect rack (the top-left button, labelled FX On) and generally you need to raise the input level and maybe the output level.
Update: I've make a few demo sounds (you'll have to excuse my terrible playing) giving some idea of Rakarrack's capabilities. They're just named after the default Rakarrack setups that I used:
Summer at the beach
Metal amp
Funk wah
Blog: Pluto, we hardly knew ye [Wednesday 11st May 2011]
On Wikipedia's Science Reference Desk, Dolphin51
points out a beautiful, perhaps sad little fact about Pluto, the little planet that couldn't...
Pluto was discovered in January 1930 - 81 years ago. Pluto takes 248 Earth years to make one orbit of the sun. So in all the time that we have known about Pluto, conferred ''planet status'' upon it, then
removed that status, it has covered only 117 degrees of arc around the sun, one-third of an orbit, or one-third of a Pluto year.
Blog: On credit card data theft [Monday 9th May 2011]
The recent theft of customer data from the
Sony Playstation Network computer system shows the continuing problem faced by anyone who has lodged their credit card information at an online merchant and allowed
automated repeat billing. It's quite reasonable for someone to have a dozen or so such ongoing relationships, and for their credit card details to be stored in the systems of as many retailers again (particularly those that check the "keep my details" box by default).
Merchants that make repeat payments on the same credit card have to keep the customer's credit card info around. This makes breaking into them a tantalising prospect for any attacker, as the merchant stores enough information to allow fresh payments to be made at any merchant, or for fake
physical cards to be manufactured. This posting discusses two proposals that allow merchants to make automated repeat payment requests on the same credit card, but without the merchant's permanent database storing that crucially re-usable credit card information.
In the examples below, the card data (CD) is a record containing the cardholder's name and the card's number, cvv, and expiry date.
1. The public-key cryptography method
- The merchant receives CD from customer
- The merchant builds a merchant+CD packet by concatenating their merchant ID (mID) with the data in the CD:
mCD=mID+name+expiry+number+cvv - The merchant encrypts the mCD with the acquirer's public key. EMCD = Eacquirer-pub(mCD)
- The merchant then forgets the name, number, and cvv fields. They keep the expiry around so they can prompt the customer to renew their card details when the card is close to expiring.
- The merchant builds their ordinary payment-approval request to the acquirer by concatenating the EMCD with details specific to the transaction (chiefly date and amount) and sends this to the acquirer over the normal encrypted channel.
- If the acquirer approves the transaction, the merchant retains the EMCD in their database along with the expiry date. For future transactions they build the payment-approval request as above, without rebuilding the EMCD.
B. The payment-token method
- The merchant receives CD from customer
- The merchant builds the normal approval transaction and sends this to the acquirer as normal.
- The acquirer approves the transaction, and as part of the approval returns a repeat-payment-token (RPT), a lengthy random number.
- The merchant forgets all the CD except the expiry, and stores the expiry and RPT in their database.
- For subsequent transactions, the merchant builds a repeat-payment-request transaction, and instead of the CD it uses the RPT. On receipt of this, the acquirer checks that the corresponding account is valid (in the normal way) and verifies that the submitting merchant is the same as created the
RPT. If the mID mismatches, the payment is declined.
In both schemes the merchant does not retain a permanent record of the customer's credit card data (bar its expiry). So if the merchant's system is compromised, and the attacker gains access to the list of customers, including all the data the company stores on them:
- these cannot be turned back into bare credit card info, as the merchant, and the attacker, don't know the acquirer's private key. So the attacker cannot generate fresh payment transactions with another merchant or manufacture a valid physical card.
- armed with the EMCD/RTP the attacker can create further transactions with this merchant, but as the merchant's stored info is specific to that merchant, it can't me used to generate transactions at another merchant.
The public-key method requires the acquirer and merchant maintain a public-key infrastructure, including key distribution, that they would not otherwise. The payment-token method does not, but requires the acquirer to store payment state for each (merchant,customer) pair.
Neither method protects against the same merchant being fooled into producing unauthorised transations, but it firewalls the damage caused by a single merchant's system being compromised to that merchant.
2010
Blog: Left Below [Thursday 16th September 2010]
The end of the world is nigh. From
The Road to
Fallout to
World War Z and
Zombieland, we're being trained to live in the world after The Catastrophe, when we have been (as the Simpsons would have it)
Left Below.
Once thing is clear: if you're one of the few survivors, nothing more useless than an electric car. At least in the short to medium term, you're going to need a good old fashioned petrol car. You can siphon fuel from other vehicles and from the tanks of petrol stations. If this is a real
apocalypse (which means almost everyone is dead) rather than a mere zombie mishap, there is essentially enough fuel for you for the rest of your life.
In the longer term (maybe a generation or two, or much less if there are more survivors) then probably a diesel car adapted to burn biodiesel is the way to go, providing you can get the feedstock for that.
But plugging your Nissan Leaf into a windmill? Only if you live beside a windmill, and don't plan on being 40 miles from it ever again.
Blog: Left 4 Dead 2 pricing and the future [Wednesday 7th April 2010]
Valve has lowered the
Steam pricing of their zombie holocaust shooter
Left4Dead2, bringing its UK price to £20. As with much of Valve's perpetual twiddling with online pricing models, it's at once clear that they're up
to something, but not at all clear what that might be.
Left4Dead2's expansion "The Passing" is due for release fairly soon; this pack will, at least for PC users, be free. So they're doing their usual thing, adding value to an existing property and stretching that long tail out
further.
Valve's physical distribution is handled for them by Electronic Arts, who (along with the physical retailer) will take a sizeable chunk of the proceeds, and who (if they have any sense) will have some deal with Valve preventing them from undercutting the retail channel with their own online
service, at least for a while.
Valve has been very experimental about pricing and packaging, and they've done an excellent job of pushing Steam out to a pretty wide footprint, and teasing us with those darn £5 game deals. While it's always nice to make £5 on some old game, when you'd otherwise not have sold anything, it's
much nicer to take all off a full-price release, and not have to share any with a distributor, a retailer, or have to spend money on little disks and manuals and other junk. So I think it's only a matter of time before Valve try their big experiment - can they make more money selling a title
only on Steam, with no physical channel at all? It's clearly where the market is going, they're in a better position than anyone to deliver, and they have two prospective titles that have people champing for the (Portal 2 and the ever elusive Half-life 2 episode 3). Both have
an established userbase that's eager for more, and all those people already have Steam. And how many people in either product's market are stuck on no-internet-ever or dialup-only machines; Valve (who see the results of Steam's occasional hardware surveys, which ask just this) know, and you can bet
it's a small and diminishing group. The question they have to ask, when embarking on an online-only distribution, isn't "can we sell more online", or "can we take more turnover online", but simply "can we make more money selling online - does the less profitable physical distribution just undercut
sales we'd get online anyway?" Providing both games are good (and again Valve have an excellent track record) they don't have too much to lose - sell online for a month and if that doesn't pan out, cut a retail deal anyway.
Sooner or later they're going to take a punt at this, unless EA or whomever chucks a wedge of money at them to shore up a leaky business model. So that's my prediction - HL2EP3 sold in one market (let's say the US) online only at introduction, with a physical release later or not at all. It's
Valve's crunch time - do you want to work for EA, or be EA?
Blog: On vacuuming [Wednesday 10th February 2010]
I just did the vacuuming (what we get to call hoovering, but maybe not
Hoovering, in the UK). It's a boring business, and one that seems like an anachronism. Why is it like this?
2009
Blog: Dead Borders walking [Monday 30th November 2009]
Borders (UK) is going out of business. On visiting a branch today, in a vain attempt to pick the corpose for any kind of worthwhile bargain, I left empty handed, surprised they stayed in business as long as they have.
I have a house full of books, and a storage locker somewhere with many more, some of which I've actually read. I love books, which means I should love book shops too. But I don't love Borders, and I won't mourn its passing.
My "local" Borders is in a hideous retail carpark with a collection of other dead-eyed boxes, where nothing ever happens and there's no reason to visit unless you really want something or truly have nothing to do. It's half an hour drive for me, and half an hour for everyone else.
The shelves tell a sorry story The "new age" section is three times the size of the "science" section (and "science" includes the lightest of popular science, all of maths and engineering, and anything DIY that looked harder than putting up shelves). "Self help" is twice the size, as is
"religion" - and "religion" is barely about religion at all, but mostly self-help books that cravenly invoke religion to sell themselves ("Jesus wants to you be thin"). When there's more books about the Christian way to stop smoking than there are bibles, and no sign of Aquinas or Boethius or
Luther or St.Teresa, it's another sign that they're beyond redemption (so to speak).
Eight quid for a 16 page kids book? A huge collection of 2009 calendars with newspaper cartoons about slippers? Discount books that don't compete with Bargain Books who pay a tenth what Borders do for retail space? Old DVDs with prices that seem designed to compete with Virgin Megastores (look
how well they did) - £9 for Casablanca? £11 for Fast Times at Ridgemont High? £12 for some thing with Jack Black in it?
Front of house, their pride and joy, Borders' strategic reserve of unsold crap. Ghostwritten celebrity junk: all called something like "My Life" or "My Way", supposedly written by someone whose life has barely started and whose only achievement is being on some program on Channel Five where they
were the outstandingly stupid person among a group of troglodytes carefully chosen by professional psychologists as being the worst possible. TV tie-ins. Celebrity recipies. Celebrity detox. Celebrity diets. Celebrity confessions. Contrite celebrity "when I got out of jail all the money was gone"
sob stories. Things one guy from Top Gear likes, and things the other guy from Top Gear hates. I am Jack's raging bile duct. And I swear the prices for this junk have gone up.
People will tell you that Borders, who happily crushed the smaller bookseller when times were good, has in turn been crushed between Tesco and Amazon. This is true, but Borders went along with it. It's no surprise that Tesco can shovel junk better and cheaper than anyone, or that prime retail
space isn't best used for selling off old calendars and discount books. With its convenience and range and prices, Amazon is darn hard to compete with, but Borders didn't innovate and really didn't look like they were trying. Relying on the "Grandma doesn't buy books off the internet" theory was a
loser for them, because Grandma turned out to be smarter than they thought.
Still, the venture capitalists who own them will have plenty of "Chicken Soup" books to read inbetween insolvency meetings.
2008
Blog: The Sherlock Holmes inversion [Sunday 28th December 2008]
Sherlock Holmes stories are told from the perspective of Dr John Watson. Sherlock is a genius, a strange mercurial creature that is somehow above the rest of us. But if the stories were told from Sherlock's perspective, they'd be
Idiocracy.
2005
Blog: Buildscripts and stuff [Friday 14th October 2005]
Ah, there's nothing like making life difficult for yourself. This site, you see, is maintained by a script of my own creation. For a very long time it's been a cygwin bash file, which at its heart is a massive find statement. This finds a bunch of html-like source files and
runs them through an html preprocessor. I use
iMatrix' HTMLPP - I can't say I particularly recommend it (it seems there's no ongoing development on it, it's a bit crufty and requires a bunch more stuff in the templated document than I'd really wish.
Ideally I'd move to a modern, supported templating system (people have recommended Clearsilver to me, and it looks nice), but the effort of changing all my sources files (of which there are around forty, plus some files that are built automatically) would be a bunch of work. The bash script which
drives this thing grew and grew, doing automatic image thumbnailing, having support to host source code files (importing them from a nearby live sourcetree and formatting them nicely), and having some
basic blogging support.
Imagemagick handled the image scaling.
A while ago I started rewriting in python, still on cygwin. I really don't know why. It was worth it, I suppose, but more complicated than I'd hoped. In a final push yesterday and today I finally finished it, and cut its dependency on external utilities that cygwin provides (sed and find and
stuff). So now it runs natively on Windows or Linux, which is a relief. Cygwin is fine as long as you stay inside the little cygwin box - but if you have to call in and out of it then you run into endless little filename-escaping issues.
The python version is certainly more verbose than its bash counterpart, but much easier to read (and, I hope, to maintain in future). Image scaling is now done by PIL rather than imagemagick (I just couldn't get PIL to work properly on
cygwin's python). Where I used hacky sed calls to do some text substitutions I now do some really botched python regexps instead (I'm more ashamed of them that I was of the sed ones, which is saying quite a lot). The whole thing has about as many lines of code (although far fewer
backslashes) and takes about the same time to run. But for exactly one line (a shell variable expansion in code called inside the macro system) it's entirely portable (damn, I'd forgotten that hideous DOS %var% syntax). I still use htmlpp to do template expansion, html tidy to fix any html snafus,
and linklint to verify that there aren't any bad links. Blogs are still built in an overly manual way, and there's still no RSS syndication.
I keep wondering whether to shift the blogging support to Wordpress (which I've goofed around with, and which couldn't be easier). I guess I'd put the Wordpress content into an iframe (where the current static blog appears now) as I don't really want the entire content served from Wordpress. I'm
squeamish about dynamically generated content when static would do, so I guess I'll have to figure out how to get it to produce static content. Urgh, I guess that's another hundred lines into the buildscript.
Blog: Backgrounds and their fans [Friday 19th August 2005]
Our morning glories are out today (and will be gone tomorrow), so I took some pretty nice photos of them. I've added the best (the plainest) as a new
background.
In checking through my webserver logs I've discovered that several teenager use my images for the backgrounds to their weblogs. Technically it would be better if they downloaded the images to their own website (instead of using up my paid-for bandwidth), but they seem like sweet people, so I'm
not going to hassle them about it. If I was particularly nasty I could write some code that checks the referrer on requests for those images, and send visitors to their site (but not mine) something horrible like the goatse man.
It's a compliment, I guess, so it'd be churlish to complain. The thing about copyright is that if I fail to defend it, someone might claim that I've abrogated my right to do so in future. The last thing I'm going to do is send a nasty cease-and-desist letter to these folks, so here's the smart
solution - the following myspace users are hereby granted licence to use images from this website on their personal weblogs:
(boy, you guys have some really overproduced websites)
Blog: Flowers [Sunday 7th August 2005]
I've been looking after my neighbour's greenhouse and the plants on his deck while he's on holiday. The weather has been lovely, which makes for much watering to be done. Although the neighbours are missing the display, I'm enjoying the flowers.
Here's some photos:
Blog: Improving how MediaWiki handles anons (users who haven't created an account) [Monday 4th April 2005]
MediaWiki, the open-source software which runs Wikipedia and many other wiki websites, allows users to edit without creating an account. This exposes these new editors' IP addresses, and makes it impossible to later associate the initial work they do with an account they
subsequently create. This proposal suggests a cookie-based scheme which aims to ameliorate some of this.
Principles for a new version
- The barrier to entry should be no higher than now
- The degree of privacy afforded to all users should be no less than now
- There should be no significant performance, data-storage, or other technical cost associated with the change
Design goals- allow a continuity of identity for anon users, so that those who use dialups or proxied-ISPs like AOL gain their own talk page and contributions record.
- allow easy, automated assignment of an anon's contributions when he/she decides to register formally.
- minimise confusion between productive contributors and vandals who share the same IP address (or proxy), and avoid sending unwitting new users the nastygrams they frequently receive now.
Implementation notes- When users visit the site, the software (as now) queries them for a cookie. Presently, if they do not return it, they are treated as anons, and known by their IP addresses. Instead, the new software will assign them a pseudonym and send them a cookie. As long as they return that cookie, they
will be known by the same pseudonym. Pseudonyms look like:
anon(00003292) where 00003292 is a sequence number. Special pages (contribs, block, watchlist, etc.) work just as if this was a real name, and the user receives their own unique talk and user talk pages. - If a user then signs up for a named account, and they're returning a cookie which associates them with an anon(xx) name, that name is renamed to the name they choose, as reflected in article edit histories, special pages, etc. The old anon(xx) user and talk pages still work, but are synonyms
(NOT redirects) for the new username. The old anon(xx) name is never recyled.
- Existing technical restrictions on anons remain - they can't move pages or upload images. Their IP addresses are still visible to administrators (but, unlike now, not to ordinary users).
- Users who accept cookies but move between different computers (and so accept a number of cookies, one at each location) will appear as a number of different anon(xx) type users. As sysops can still see their IP address, it is still possible for them to correlate multiple accounts, in case of
vandalism (and for computing rangeblocks).
- Some sysop views of pages automatically show the anon(xx)'s real IP address. These include:
- special:contributions
- user:anon(xx)
- user talk:anon(xx)
- special:log/block
- article histories And admins can see all the anon(xx) who have edited on an IP - with the exception of users who have subsequently registered.
Limitations- Users whose browsers are set up to reject cookies will appear as a new anonXXX on each edit.
- Vandals and vandalbots will naturally not likely to accept cookies (or will attempt to return forged ones)
Because of these limitations, it may be necessary to drop the protection afforded to anons when the anon declines cookies, and instead show their username as "anon(99.0.138.4)" - this is visible to all users (hmm, or maybe to all signed-in users) to help them track serial vandals from rolling-IP
addresses.
NotesThis isn't intended to be an extra security measure, and the cookie isn't intended to be secret. No "security by obscurity" is intended, although in practice this will help track many of the more casual AOL (etc.) vandals. Its primary purpose is to make life easier for anons; although it
benefits others in making it a bit easier to track some anons, it's not accurate enough to be a "perfect tracking" solution.
As an optional implementation feature, creating an account can go through a degree of verification (recognise-the-text, email) - this will mostly be a barrier to the forthcoming generation of mass vandalbots.
Blog: Genomic Cartography [Saturday 2nd April 2005]
Cool thing of the day: Ben Fry's researches into
Genomic Cartography. Ben has some very interesting looking (heck, I can't tell if it's really useful, but it looks nice) means of graphically depicting genetic
information. Some of Ben's graphics were used in
The Hulk (but don't hold that against him).
Blog: Untrusted signed applets [Saturday 2nd April 2005]
I see there's a new "bug" in Firefox about
handling for Java applets with unknown security certificates. It's filed against Firefox, but Opera does it too. Is it a Java bug? I
think
Internet Explorer works the same way too. It is a bug, but it's a UI bug, and the general bad pattern isn't limited to Java at all.
The exploit in question uses a signed Java applet to install malware. The signer isn't trusted, so the browser pops up a dialog saying the security certificate was issued by a company that is not trusted. That's a major red flag to a technically-minded user, but it's meaningless
technobabble to everyone else (the majority of any browser's user population). Firefox, and other browsers in similar circumstances, is (naively) doing the right thing by showing this. But the great majority of the user population is unable to give informed consent to this nonsensical question.
Presented with these things periodically they soon realise that clicking "yes" makes things work, and "no" makes things break. Thus they become conditioned to clicking "yes" every time. They don't know what they're doing, but it's not their fault - they're being asked a question they can't possibly
understand.
The fix is easy. The default setup for the browser should be to siliently ignore attempts by such programs to work. No dialogs. No questions. No little warning icon. In order to be even asked the question, a user should have enough technical nous to be able to hunt through a menu and find an
option to turn it on. And frankly, even as an "advanced" user, I want to have to turn on even being asked on a per-domain basis (although I'd like a little warning triangle in the corner when an unsigned control is being thwarted, much like the warning I get for blocked popups).
This pattern of asking for uninformed consent is getting pretty common. Personal firewalls are very prone to doing it, asking nontechnical users even more abstruse networking questions that they've no hope of understanding. It's not informed consent, and if the person can't reasonably be asked
to give it, it shouldn't be requested in the first place.
Blog: The cold dry(ish) west [Wednesday 23rd February 2005]
I'm back from holiday in the US. This began hanging out with some old, good friends back in the Bay Area. Nothing really changes, although the traffic appears to have recovered back to its dot-com-bubble level. Absent the dot-coms that used to eat everyone's spare time, it seems there has been much
making of babies, which makes me feel rather old. After babies come lawns. Then sheds. Sheds are the little death.
This was followed by snowboarding in Lake Tahoe. I really can't snowboard, and I do it so infrequently that I forget almost everything in the two or three years between sessions. So this time I squished in a rib (opinions differ as to whether it's technically cracked; it sure hurts enough),
twisted an elbow in an unfortunate (but not serious) direction, and probably did my liver irrevocable damage with all that endless apres-ski. Still, I had a lot of fun - if only Scottish ski resorts were as fancy as Squaw Valley and Heavenly. If only Scottish ski resorts had more (like any) snow,
and more (like any) sunshine. Perhaps I should invent "rainboarding"?
Here are some photos:
After that back to the bay area for a couple of days, including a fancy meal at a faux-sixties place in San Francisco (oh, fine dining is wasted on me) and then off on the longest drive of my life. From Oakland to Barstow (boy, that's not a very interesting place), then a day and a half
in Death Valley (sleeping in Beatty, NV, as the accomodation in the valley is unpleasantly expensive). Death Valley blew me away: I've never been anywhere so big, so bleak, and so empty. In the middle of this desolation the little desert
flowers were blooming (this, apparently, is one of the best seasons for them in years). It's strange - the smell convinces you that you're at the seaside and it's just low tide. There are salty tide pools and the landform feels just like the seaside. It took more than a day before I could persuade
myself that the tide really wasn't coming back in. It would be a great place for backpacking or biking (in the winter; I don't fancy being there in the summer at all). I also visited Scotty's Castle, which wasn't really very
interesting.
More photos:
After that I'd planned on spending a day in Las Vegas before driving further east. It poured with rain, and I figured that I didn't want to be trying to have an outdoor part of the holiday during the rain, so I spent two nights there. I'm really not overly fond of Las Vegas: I don't gamble, don't
want to spend $100 to see Wayne Newton, and I'm generally immune to (or deathly afraid of) most of the other modes of sin that Vegas had to offer. So frankly I was rather bored. I did drive out to the Hoover Dam, which was impressive. The tour wasn't, however, and they neglect to tell you how
limited it is when they're taking your money. Apparently the tour went to several places inside the dam - I really wanted to see the dam from below. Not any more; I can't conceive of Al Qaida blowing it up - it's about the least explodabling thing in the country. They take you down to the gallery
above the turbine hall, you look at it for about two minutes, and then they take you back up. Apart from that it's the usual diorama visitor centre type stuff.
From Vegas I drove west to Flagstaff and then north over Coconino (at night, in a fair amount of snow) to Tusayan. The following morning I help an English guy at the gas station, who can't figure out how to pump gas. The first time I did this in the US (a long time ago now) I got similarly
confused. In Britain you pump then pay, but in the US it's the other way around - which means if you're silly enough to pay in cash you have to guess how much, or overpay and then go back for change. Plus there's the pointless handle you have to lift to make the pump work (I've never found any need
for that).
The vistor stuff at the south rim is way touristy, and one is left walking a tame little path with hundreds of bickering teenagers. I'm a bit underwhelmed, but that's probably entirely a function of only being at the tame top, and not having time to venture down into the canyon itself.
Photos:
Kayenta, like the rest of the Navajo Nation, is dry (alcohol wise); I wonder if the case of beer in the back of the truck will get me into trouble. Not to worry; I only see one Tribal Police vehicle in my entire time in the nation, haring down the road on some vital mission. Every layby off the
road is strewn with bottles, so I guess that's what the kids do when the TV is bad.
Monument Valley is big, and impressive, and certainly worth the (rather hefty) trip. Like (almost) everwhere else on this trip, I wish I had a lot more time to explore properly, and to do so on foot. Even from the tame road around the easy bit, it's an incredible place.
You get that same uneasy feeling you do in any inhabited touristy place - the people there want your money, but they really don't want you. There are signs asking you not to take photos of people's homes (or, rather, signs saying you'll have to pay to do so). I don't take any; doing so would
seem to require rather too much of a condescending "oh look at the quaint little houses the poor people live in" attitude. This is the poorest place I've been in the US, and it's noteworthy how many "Support Our Troops" signs there are here; I don't know what else folks would do for work.
Here's four photos of the valley. Even after pouring over the USGS geodetic map I still can't figure out which mesa is which, so if someone can help me with that, I'd grateful:
It should be possible to figure everything out from the annotated
aerial photo I submitted to Wikipedia a long time ago.
I didn't go to Canyon de Chelly, largely due to not bothering to read the next few pages in my guidebook. I did briefly stray into Utah (my first time) after I missed the Monument Valley turnoff, and I'm glad (and slightly surprised) to
report that I didn't instantly turn into a pillar of salt. Worse, I didn't leave time for Arizona's meteor crater (something I only noticed on the map once I'd gotten to Phoenix).
From there it's a long drive south to Flagstaff and then down into Phoenix. I didn't have much time in Phoenix (I didn't arrive until way after nightfall) so I can't say much about it. Well, other than everyone drives very fast and the highway numbering is crazy.
Now, one question I need to address is the sat-nav issue. My Dad has a TomTomGO unit, which he's very impressed with (I less so, having been sent some weird roads in southern Glasgow by it). I could have spent £100 on the US mapset for it, and I probably
wouldn't have gotten lost. I did get lost, but not drastically. I can never navigate around suburban east Oakland, but the Tom Tom sometimes lets you down in such places. Flagstaff's freeway signage confused me a fair amount, and Phoenix was terrible. Vegas was easy, and every other town I was in
only had one street. So I'm on the fence - I may have wasted two or three hours over the whole trip driving on the wrong road; on the upside, I didn't have to worry about whether to leave that expensive satnav unit in the car overnight.
2004
Blog: Barcelona holiday [Friday 31st December 2004]

I'm just back from a two and a bit day trip to Barcelona with a friend of mine. Wow, that was a much better
place to celebrate my birthday than dark chilly Scotland (not that it wasn't pretty chilly in Barcelona, particularly when we (rather foolishly) went wading in the Mediterranean.
I've you've not been, I couldn't recommend it enough. Beautiful, clean, friendly people, nice architecture, lots of interesting stuff to do. The food was great - I don't know how I'm going to go back to eating my own cooking after living on delicious, cheap, and varied tapas. Like all "ethnic"
food, the less you pay for it (and the plainer the place you buy it) the better it is. We ate in one place under the Montjuic which served us each a fish, three slices of tortilla espanola each, and two (eerily British) desserts. That and a bottle of water and a bottle of Estrella beer (the latter
for me, naturally), and the total cost came to eleven euros. Heck, you couldn't eat from McDonalds for that (and they barbarically don't serve beer).
How hard can a Spanish omlette really be? (I may have to consult Delia on that one, hopefully she does more stuff than just Yorkshire pudding). Naturally I took a bunch of pictures (it's so nice to be somewhere where there's enough light for cameras to actually work properly).
Blog: Windows Connection Sharing's identity crisis [Saturday 18th December 2004]
When is an internet connection not itself? When it's on a different USB port. Sometimes.
The lab machine, the only machine that needs to stay turned on all the time, is a pretty decent Windows XP machine. It's usually the only Windows machine in the building, and as with other things Windows its a disproportionate source of problems. It connects to the broadband connection via a USB
802.11n connection. From there, via "windows connection sharing" (Microsoft's NAT implementation) it distributes the connection to the rest of the mcwalter.org lab (via good ol' ethernet).
Last week the lab machines lost their visibility of the internet. They could still see the windows box, and it they, and it could see the internet fine. Usually one would blame the windows firewall, but even with it switched off the problem remains. The cause, it turns out, is another piece of
Windows' odd world view. See, at some point I'd pulled out the USB connection to the 802.11b adapter and (in tidying cables) had plugged it back in a different USB port. Now, I'd say what uniquely (and solely) identifies a network adapter is its MAC address (which is encoded into adapter itself) -
but windows cares which USB port it's plugged into. Plug the same adapter into a different port and windows thinks that it's a different connection. That's a pretty odd way of thinking, but I suppose it was something no-one had to think about before USB (ethernet and serial ports, after all, have
an unbreakable link between their physical location and means by which they connect to the host pc). Windows' NAT works by designating one connection (essentially the upstream) to be the shared connection. By plugging the adapter into a different port, the shared connection wasn't present, and so
there wasn't a shared connection, and so the other machines couldn't see the internet. By redesignating this new connection as the shared one I restored the other machines' ability to talk to the internet.
So, Windows is stupid. Plugging the same adapter into a different USB port should be transparent to the ethernet layer above it, never mind the IP layers above that.
But waitadarnminnit. That wireless connection is protected by WEP (heck, it's all the cheapo adapter will support). So the properties sheet for the connection stores the network key. When I connected the adapter to a different port and made a new connection, with a new connection name,
the main windows machine should have lost its wireless connection. Should, but didn't. The new connection got the same key, and indeed the same gateway address and DNS setting and netmask - because windows saw they had the same adapter, and so figured out it was the same connection. Sigh. So
one part of the windows networking stack realises that my new connection is the same as the old one, but another part (a part which knows far more about USB than it should) doesn't concur.
Blog: QNX: ups and downs [Saturday 20th November 2004]
QNX, makers of the eponymous RTOS, are making it available for personal usage. I've done quite a bit of work on it for several project recently - it's pretty good, but working with the company has proved to be rather less fun.
This post is adapted from an anonymous post I made on Slashdot earlier
To clarify, Neutrino is the (current) OS and QNX is the company (to confuse things, QNX used to make an x86-only OS called "QNX" or "QNX-OS", which is quite similar to, but not the same as, the multi-architecture neutrino).
I have some experience of both programming for Neutrino and some business-development work on projects aiming to deploy neutrino. I have both very positive and rather negative things to report.
On the upside, the Neutrino OS is generally excellent. It's very responsive (from a real time perspective) and the system and device APIs are nice and clean, pleasantly symmetric, and well thought out. Writing device drivers is a much more pleasant business than it is on Linux or Windows. The
microkernel stuff really isn't visible to a user, but it makes the low-level developer's life a deal easier. There's a great satisfaction to recompiling a video driver, slaying the current instance and executing a fresh one, and have the whole thing work without a reboot.
Photon is okay. It's fast but rather old-fashioned, and its C API is crufty and rather a pain to code in. It's rather thin on higher-functionality widgets and one has to do more heavy lifting when implementing one's own widgets that I'm used to. It doesn't have a more modern graphics API (like
GDI+/quartz/java2d) and that's a bit limiting when one intends to use it for TV/Video stuff (settop boxes etc.); again, I can do it myself, but it's more heavy lifting than I'd expect on other OSes. Support for audio and media is so-so, and I don't believe there's any 3d support. None of this is a
problem if you view Neutrino as a high-end embedded OS (as opposed to a desktop OS) but even there - I'd rather not implement a nice post-Tivo setop UI or a high-end incar navigation system on Neutrino - it's all doable, but its rather too much work. Photon is clearly architected for speed and
real-timey-ness (it's single threaded, like Swing, but being in C one doesn't have access to some nice little things that make Swing programming more tractable, like invokeLater), rather at the expense of programmer friendliness. One has to ask, however, if it's really worth the time
of the idle user learning photon, and the low number of free and open source (and heck, commercial) programs using it shows that most developers haven't learned it. There is an X-server for neutrino, but I really don't know anything about it or the degree of toolkit support on it.
The real problem with Neutrino is (or was, maybe things will change under the new regime) QNX (the company) and their business model for selling neutrino. It's not that they're dumb or mean guys, but things conspire to make the independent developer's life (and particularly the free/open-source
developer's life) discouraging. Here's some of the problems I faced:
- Neutrino is closed source, and in practice much more closed than say Solaris on Windows. There's a lot less example code floating around, either from official sources or other developers, and QNX's documentation is mostly "what this call does" not "how to do XXX".
- QNX's support (the paid, and not at all cheap, support) isn't all that good, and several times has seemed like a branch of the sales department - a couple of times I asked for API docs for module interfaces that clearly existed (as QNX insiders had written a bunch of plugins of one kind or
another) and was told I could (for a significant price) licence the source code to the particular element. That's no good - first off I don't really think I should have to pay (again) for just an API, and secondly I really don't want to be reading through some code to answer my question.
- QNX is a pretty small company, and its engineers have their hands full. So device support is limited and rather behind-the-times. Folks have a view of embedded systems that they're little boxes like Audrey, but a firewall or an airport-information-system or a storage array can be a pretty
big-ass piece of iron, and it's reasonable to expect to use some new, high-end cards. Bar some drivers ported over from xfree86, QNX's answer seems to be "our custom-engineering department will write it for you". Again, I understand why things are this way, but that doesn't make it encouraging, and
when I can turn around and get a free or low-cost driver for windows or linux or (increasingly) for VxWorks, it makes choosing neutrino harder.
- Community and print resources are poor. There are essentially no print books about programming neutrino, other than a rather scanty book that QNX give you (when you buy the rather expensive professional momentics dev package). Yeah, there is one (core-OS centric) programming Neutrino book, but
it's out of print (amazon couldn't find me a used copy after months of trying). All the other stuff (networking, graphics, photon, media, device-specific stuff) isn't covered at all. Similarly newsgroups and mailing lists are very limited.
- And lastly (this is just a gripe, really, but I think it's indicative of QNX's attitude in general) is the FUCKING licence manager on the windows-hosted platform for momentics. You pay a ton for a single developer seat and have to waste days diagnosting problems with the stupid portions of the
system not taking to the dumbass licence manager, or its being misconfigured in some silly, hard to find, no-diagnostics way. Support is largely clueless about this. It's all the more frustrating because the toolchain works without licence-bollocks when hosted on a neutrino machine (great, so I
need another machine in my teeny office) and they're mostly protecting a version of the GCC toolchain and the eclipse IDE.
So Neutrino is pretty good in its little embedded/control space. It has great potential to be much more, but I can't see how it'll get out of its current space. Just as Linux benefits from a virtuous circle of support, features, and acceptance, Neutrino suffers from a vicious one. Why code for
it when there's so few users and the tools and docs are second-rate? Why improve the tools and docs when there are so few programmers. Why try to help expand the neutrino community when QNX aren't really terribly motivated to help you.
It's been clear for a while that QNX (the company) have been under financial pressure. I guess they're getting squeezed on one side by VxWorks and on the other by Linux. I'd hoped they'd find a way out of their niche (perhaps by open-sourcing some core stuff, perhaps some other means) but their
being a remote division of a speaker company surely won't make that likely.
I conclusion: nice (core) technology, but a business model that hasn't kept pace with the times.
Update (years later): For context, "Audrey" in the post above is the old 3Com Audrey internet appliance.
Blog: Autumn photos [Tuesday 2nd November 2004]
Season of mists and mellow fruitfulness. And lots of rain. I've taken a few nice photos between the rainstorms.
Blog: California's flowers [Friday 20th August 2004]
I've added
Some more photos from California (the last lot, I think).
They're all of flowers, taken in the garden of a friend of mine. You know, I'm really not particularly a fan of flowers in general, but if you want to take a beautiful photo quickly and cheaply, it's really hard to get a better and more convenient source that some little flower growing in an
unused patch of land.
Also, by popular demand (not least from me) I've chopped the photos page into sub-pages, sorted "thematically". So, while there's still an overall index page, things are also grouped into more easily downloadable sections.
Blog: Wikis don't work for conversations [Tuesday 10th August 2004]
Most wiki sites have some kind of talk or discussion page, and the larger ones have fairly extensive processes, much of which implements structured things like multi-threaded conversations, staged processes, and sometimes voting - all made with the common clay of wiki.
Wiki is great for the task for which it was intended. It's great for collaborative editing of text. To date it's pretty much useless for collaborative editing of anything else (there's no reason once couldn't have a graphics wiki or a midi wiki, for example, but no-one has written the
tools to do this).
Wiki isn't great for conversation, isn't great for process (which is workflow-managemant, I suppose) and really isn't good at all for voting.
- Archiving is hard - pages grow to large sizes, so someone deletes bits or moves bits or archives the whole thing in some repository and the discussion starts anew. This all has to be done manually, and it destroyes the flow of the discussions. As there's no structure to the discussion, there
are no logical points at which to perform such an archiving procedure, and there are no clues to allow either people or software to later reconstruct the stream of what was going on.
- You can't permalink a comment or a discussion-tree. If it gets altered or deleted or archived, it's essentially lost (sure, it's in there somewhere, but in a form that means you have to go searching for it.
- It's almost impossible to syndicate and aggregate. There's no "we're done now" event in wiki, beyond the simplest edit-update. As edits can (and frequently do) go back and touch previous content (inserting comments, fixing bad links, reformatting, etc.) a naive RSS channel of a single wikipage
would be filled with trivial update edits (and with no way of telling the client to glue all the little changes together into a single object).
- There is no structure to conversations, other than arbitrary conventions (often formatting-based). So it can be hard to follow a conversation, hard to see how an old discussion got into the present state, and there are no cues to allow software tools to figure out what's going on. So there's no
way to automatically filter (in or out) a discussion or a thread that's happening on a wikipage which has multiple things going on simultaneously.
- The very plasticity of the wiki medium means that one person's comments are subject to infinite alteration by others. Although serious cases of this tend to be quite rare, one has to be a skilled operator of the change-history system of the particular wiki to figure out if, when, and by whom a
(sometimes very subtle) change has been introduced. With those wiki systems which don't have history (or don't present it publiclly in a very useful way) then it can be almost impossible. Votes can be tampered with, and conversations altered to make the guilty appear innocent and the innocent
guilty. Worse, if a discussion is subsequently archived (using the common cut'n'paste archival method) then the history is essentially lost.
- Voting is cumbersome, needs manual intervention, and is susceptible to fraud. Wikis often need to vote (what to delete, promote, laud, fix, move, rename, split, join, and what general policies and proceedures need to be adopted). Votes are conducted as general wiki conversations, and have all
the problems associated with those, and some special ones of their own.
- There's no means of checking that a given voter is qualified, and has voted only once. (this has to be done manually, something that doesn't scale well)
- Managing more complex voting systems (such as transferrable voting) makes for more manual labour.
- Discussions get muddled with votes, and untangling the two can be a tiresome (and yet again, entirely manual) business.
- As with all wiki discussions, there's room for deliberate vote-tampering (by changing or manufacturing votes by others, or deleting unfavourable votes altogether). There's also room for entirely innocent accidental vote alteration or deletion.
- There are no hooks from which to hang a decent workflow system.
Items need to be created, edited, checked, cleared, approved, and published. This isn't so much of a issue for an edit-forever public wiki like Wikitravel or Memory Alpha, but wikis which produce works in a finite
time (such as those in professional organisations) may find the discussion of work and the actual work done itself dislocated. Resolution of discussions and concomitant changes in the work items must be done manually.
To be fair, wikis weren't really built with workflow management and automation in mind, and don't have support for it anywhere, not just in the discussion pages.
So enough with the griping - clearly things aren't ideal (although even big wikis like wikipedia muddle through). For things to work better, and in particular scale up successfully, a wiki site (not necessarily, although ideally, the wiki software itself) needs to exhibit much of the behaviour of a
bulletin board. So I'd suggest using some preexisting forum software, handled this:
- The forum needs to have proper permalink and thread handling, and its interface should be able to present these sensibly (with permalinks obvious and with the user being able to open and close the "treeview" of a given thread or threads.
- As this is a discussion about the wiki or its contents, users must be able to embed wikimarkup (including wikilinks, images, tables, templates, etc.) into forum items.
- As there still all advantages to collaborative editing of "meta information" such as discussions, the system either shouldn't replace talk pages entirely or (better, I think) forum entries can have a "is editable" field (which can be changed only by the original creator of that item). Editable
items behave exactly like miniature wikipages (and if the permalink code works properly, should be able to stand alone as templates or macros).
- The forum should be integrated with the wiki's user account management system, including single sign-on and support for common policies (administrators, banning, flood prevention).
- Integration with the wiki software's UI, including common stylesheet elements and proper cross referencing between the discussion and the article interfaces.
In particular, the separation between pages and talk pages (which software like
mediawiki maintains) can be viewed as being rather arbitrary. With proper display-time inclusion there should be no reason why discussions or discussion elements couldn't
be transcluded into pages, or why pages couldn't form (statically or dynamically) parts of ongoing discussions.
Blog: New photos from the states [Sunday 1st August 2004]

Here are some more of the photos taken on my recent holiday. They're all from California (indeed, they were all
taken on the same day, a lengthy but high-speed drive up the Sonoma and Mendocino coasts of California). There don't seem to be any decent ones of New York City (it was terribly humid), other than some rather dull ones of the (very disappointing) Guggenheim museum I added to the corresponding
article on the
Wikipedia.
- basking, a photo of some seals (harbour seals, perhaps?) basking on a sandbank on the Pacific coast of Sonoma County, California, just where the Russian River flows into the ocean.
- sonoma_coast, some of the amazing rock formations that dot the Sonoma County coast. These are also from the Russian River area, taken rather early in the morning (hence the unfortunate sea mist). I saw some similar formations further up the coast (near
Elk) later in the day, but by that point I was late for an appointment in Oakland (which is far from Elk) so had no time to stop.
- golden_gate, a shot of the Golden Gate bridge taken from the Marin side (following, incidentally, my getting horribly lost in the Presidio while driving a gigantic rental truck). You can see parts of San Francisco, particularly that TV
transmitter tower (Sutro Tower, I believe it's called).
- breakers, a shot of Pacific waves breaking on the shore of Manchester State Beach, just north of Point Arena. Man, I stood in that damn ocean for ages, alternately freezing my feet off in the icey water
or burning them on the blazing sand.
- shimmer, a simple texture shot of the receeding water, again near Point Arena.
- foam, another texture shot, showing that frigid oceanwater. I'll spare y'all the numerous photos of my bare feet turning blue.
- driftwood, a shot of an interesting structure someone built from driftood on Manchester State Beach. Visible in the background is the Point Arena lighthouse, which is (apparently) the tallest on the west coast of the US. You'll notice I've managed to
entirely avoid that tired photo cliche, where we try to draw some lame allegory where the driftwood symbolises death or corruption or something. Nope, it's just a pile of wood on a beach. Sorry.
Blog: New backgrounds [Wednesday 28th July 2004]

I'm back from America (technically I was back more than a week ago, but I'm only just crawling
out from under the mountain of jetlag). I've not taken many nice photos (I decided it would be more fun to actually have a real holiday, rather than drive around places as a slave to my evil overbearing camera). I'll add some photos in a couple of days.
In the meantime, I've moved mcwalter.org and mcwalter.net from their prior home at plugsocket.com. There's nothing particularly wrong with Plugsocket (other than they're maybe rather overpriced) but they don't offer java or python and their config panel is
the aging Sun Cobalt thing (which is fine, but horribly limited). So we're moving (or have moved, hopefully) to javaservlethosting.com. The DNS update has taken here, so I see the new version, and it seems to work fine, and at least seems to
be a bit faster than before.
In a fit of getting stuff done, I've added some background images that have been sitting around waiting to be put up for ages. There's the three:
- sky, an attractive sunset taken from Stirling's King's Park last month
- usbkey, a supposedly artistic closeup photograph of my little USB flash memory key
- lily, a cute (in a blurry kind of way) photo of a nice spotted lily. This one was taken in someone's garden in California. No, really.
Blog: Off on holiday [Thursday 1st July 2004]
Woo-hoo! Tomorrow I'm off on holiday to the US, for a fun packed fortnight sleeping on my friends' couches and making a general imposition of myself. Although I've been back and forward to the states for years, this will be my first time travelling through the much maligned
Newark airport (which seems to be called Newark Liberty Interational Airport now - surely they're not still on that "freedom fries" thing, are they?).
My clever travel agent (a very friendly German chap at Stirling University's in-house travel agent) pointed out that I could take as long as I wanted for a layover at Newark - so I'm taking a couple of days in New York on the way back. I expect to suffer a bit from the humidity (hell, I complain
the scottish summer is too humid) but nothing ventured nothing gained.
Blog: Kinky blossoms [Monday 3rd May 2004]

It's spring here, at long last, and everything has come back to life. It's funny, you really don't
notice
these things usually (at least I never really have). It's easy to complain about tourists viewing their own holiday through the viewfinder of their camera, but one really doesn't see things properly until one actually looks, until one is perpetually scouting for a half-decent photo.
The cherry trees are in blossom now, and the japanese maple tree seems to have grown a whole new set of foliage virtually overnight. So for this month or so my little part of Scotland looks, to some extent at least, like Kyoto.
Of the usual myriad of sub-mapplethorpian flower photos I've only added the following three:
It's becoming clear that there's too many flower photos, in particular that the twenty or so crocus ones really are too similar to one another to justify their all being there. I'll have to thin them out somehow, but how does one choose between one's children?
Blog: New photos, new section [Tuesday 20th April 2004]

Many additions to the images gallery.
So, more of the same old faire. I've also deleted a few of the previous
fire images, the editorial commission having stricken them (at least, I
think I've striken the ones they told me to).
More exitingly (?), I've also made a new section, presenting images suitable for you to download and use as the background on your PC. Frankly, they're not really all that good, so I doubt they'll actually compete with that one of Halle Berry's boobs that you're already using, but I can life in
hope. Take a look a the backgrounds section. Your feedback, including technical feedback, is most welcome.
Blog: Wet daffodil photos [Saturday 3rd April 2004]

Unusual weather today - alternately blazing sunshine and heavy rain (although not both at quite the same
time, which is something one sometimes gets in Scotland in the spring).
I've taken a bunch of my trademark (hackneyed?) low-level photos of daffodils growing in on the lawn of the HQ of Central Scotland Police. I'm quite glad they didn't take ill to my standing around on their lawn taking photos, all too many of which have images of their (rather unattractive)
buildings, antennas etc.
The two photos I've added to the image page are:
If you look carefully, you can (just) see beads of water left over from the rain which had just ended (and which returned to soak me on the walk home).
Blog: Straw burning photos [Friday 2nd April 2004]

I've added some images of farmworkers buring stubble to the
images archive.
This was taken recently, on a rather soggy day in late March 2004. I was always under the impression that such burning was generally done in the Autumn after the growing season. Still, it was a very welcome distraction. Taking the photos, walking around on the burning field, and talking to the
workers (who didn't really seem to be having as much fun as one might think they would) nicely took my mind off the otherwise interminable fishing trip on which I'd been dragged. No, I don't like fishing one bit, even if we did catch a fish (which we didn't).
If it's not clear from the photos what they were doing (yes, it really isn't) the workers had long (maybe three metres) wires with some kind of fuel-filled rags tied to the far end. They walked back and forward across the field, leaving a (rather unimpressive, frankly) trail of fire behind them.
If the flames appear at all scary in the shots then that's entirely a function of my being about six inches away, with the camera right down on the ground.
2003
Blog: The new new spam [Monday 27th October 2003]
In the battle of the spam email, the tide has turned. Open relays are rare when they were once the norm, and modern baysian filters now reject all but the most illegible email spams. As noted spam-fighter Paul Graham wrote in August 2003
"so far, so good".
But spammers are professional, they're technical (or rather, those who write spamware are), and they have a strong impetus (profit) to continue in their line of work. Their goal isn't to send email, per se - the want user impressions, and they don't really care how they get them. Hitherto
email and newsnet spam has been the easiest way, and so they've mostly stayed there. With email becoming a less hospitable environment, they're going to move elsewhere. They already are.
BBC news reports "spammers are targeting blogs". Equally, instant messenger and chat spam is now commonplace. This isn't a diversion - this will be the new battleground for junk postings. It'll follow the same trajectory as
it did for mail, and it will be just as hard to stop.
Any website which allows users (anonymous or registered) to make changes to the website which other visitors can see will be used. Some examples include:
What the spammers will do:
- Insert their (textual) spam copy directly into pages
- Insert graphics, applets, flash, or other media directly into pages
- Insert DHTML code that pops up windows directing visitors to their own content
- Add links to their own content, in the guise of ligitimate content
- (in media where alterations can be made, such as wiki) subtly alter existing internal and external links to point instead to the spammer's content
How the spammers will do this:
- Where anonymous changes are possible, that's what they'll use
- Where access is uncontrolled but IP addresses are public, they'll keep as large a pool of addresses as they can, and use each address on as many sites as possible (a horizontal distribution). This makes a single site's blocking an existing address as ineffective as possible. Rather than flood,
some of these accounts will perform incremental changes in a piecemeal fashion. A block of text or a URL will be tranformed from valid to spam not in one go but by steps, where each step doesn't make editors or reviewers particularly suspicious.
- Where registration is mandatory, they'll register using throwaway email addresses (they've already got plenty of those). For a while (until they're blocked) they'll have multiple accounts per site per email address. They'll setup SMTP servers on dialup accounts to handle these.
- They'll create sophisticated, site-specific scripts to make their changes. The more heavily policed a site is, the more clever these scripts will become.
- Where sites are policed (and obvious spam quickly removed) they'll have their scripts cut valid content from other pages or posts on the site, make some (less than obvious) spam changes, and repost this as a new entry, page, or post on that same site. This will, in general, produce content that
will pass a cursory screen by overworked editors.
- One of the goals of the spammer is to have their spam posting persist for as long as possible. Ideally it'll be picked up by a search engine, and wholesale spamming of various groups and sites will be one way in which spammers attempt to elevate their google pagerank.
What can be done to stop them, or at least limit their activities:
- both to protect against HTML/DHTML spam and for security reasons, sites need to be very dillignet about escaping or removing html tags
- anonymous changes are problematic, and will be the most frequently abused. Some sites will disallow anonymous access altogether
- email sites already have countermeasures present to prevent new accounts being created be scripts - these generally rely on asking the client to do something that humans find easy and machines hard (such as recognising text on a noisy field). Spammers have ways around these, but this slows them
down. Websites will encorporate similar countermeasures.
- blacklists of IP addresses and email accounts can be distributed between sites (via some kind of clearing-house facility). This is more useful for "webspam" (which is persistent) than for email spam (in which cases the spammer has already abandoned the address before it gets blacklisted). For
webspam, once an address is identified as bad, all subscribing sites can flag or remove all postings that match it.
Spam filters put a darwinian pressure on spam and spammers, either to adapt to more effective spam, or to move to a new area where it's easier to operate. Similarly, spam in new venues will put pressure on software for communities, chat, wikis or blogs to adapt or be swamped (as email has) to
the verge of being useless. In the meantime, get ready for a web that sucks (in places) as much as email does now.
Blog: Dumyat photo [Monday 20th October 2003]

I've added another image to the image archive.
This photograph, which I took on a horribly hot and humid day this summer. It shows the lower summit of the hill called Dumyat, which overlooks Stirling in Scotland. Down there in the bluisish murky haze one can just see the Abbey Craig, which is topped by the monument to William Wallace.
That purple stuff is patches of heather. It really does grow in that weird pattern, and it really is that colour (infact, it's far more vibrant, but my camera is rather too poor at capturing colour to properly display what it really looks like).
This is probably going to be the last image update for a while (unless I dredge something up from my rather extensive image archive). I have to confess to having broken my trusty Canon digital camera (note to self: don't leave expensive things on the roof of the car). It actually doesn't look
too badly damaged (and perhaps needs just some kind of camera-orthopedics), but it'll need fixed.
Blog: Tree photo [Sunday 19th October 2003]

I've added yet another photograph, this time of a tree on the moors, to the photo archive. I hope y'all like it.
For the geogeeks among you, it's on the Sheriffmuir above Stirling in Scotland, pretty close to Dunblane. The view is from Sheriffmuir road looking roughly North West, over the valley to the Trossachs. Right beside the cellphone mast, and a large and depressingly modern farm (farmers just don't
want to pander to the rustic stereotypes of we jaded urbanites). It's also surrounded by some blackface sheep, which manged to perpetually be in the way and almost never in a cute photographic pose - the only decent photo I have of any of them is a "L.A. style" driveby photo, with only half of a
rather angry looking ewe in it.
I have at least a hundred photos of the same area, all taken on the same evening. It's perhaps the curse of using a camera with automatic exposure control that each picture either shows the amazing sky or shows details of the dark landscape. This falls from the latter catagory - the sky was
infact infinitely more grand that it appears here.
Blog: Mountain photo [Tuesday 14th October 2003]
Another addition to the photo page -

this time a shot of the just-snowcapped Grampian mountains in Scotland.
Sorry, mountain fans, I've really no idea which mountains these are - they're somewhere on the road between Aviemore and Pitlochry (but then, there's lots of mountains between those two places, so that probably doesn't help much). Again, this is a product of the same holiday as
yesterday's seal pictures.
Aviemore has a rather bad reputation in Scotland (and particularly in the acid pages of certain guidebooks), as it's long been a concrete ski dormitory. It's really not that bad (having, apparently, been tidied up over the past few years). It's still trying desperately to be a "proper" skitown,
but it's got a long way to go before it's Aspen or Zermatt, although it feels just a teensy bit like Tahoe City (which isn't all that impressive, but still). Frankly, after endless one-street Scottish towns and villages which feature only a drab tearoom and a "heritage centre" (note: "heritage
centre" appears to be code for "shop"), Aviemore is a breath of fresh air.
Blog: Seal photos [Monday 13rd October 2003]
I've recently returned from a short holiday touring around Scotland with my Californian friend.

Frankly, I really don't understand why americans think October is a suitable time to visit Scotland, particularly when they want to visit the scenic but notoriously rainy west coast. I suppose it's as silly as Scotsmen holidaying in Orlando in August.
Some of our time was spent at the Scottish Sea Life Sanctuary on Loch Creran near Oban. It's a great place ; don't let that ugly-ass website fool you - they're much better at fish and seals and stuff than they are at website design.
The seal pups there messed around with us terribly, hanging around looking as cute as possible and then zooming off into the murk as we fumbled vainly for our cameras. I did manage to capture a couple of decent images (and over a hundred rotten ones). I've uploaded the decent ones in the
'animals' section of the photo page (warning: nauseating cuteness ahead).
Blog: Overcoming the tyranny of GIF [Sunday 12nd October 2003]
Will we ever be free of the tyranny of GIF? Not at this rate. We need to upgrade modern browsers so we can move on without breaking older, smaller, and more specialised browsers.
Apart from the legal problems associated with the format, GIF is technically outmoded, lacks decent colour imaging, has no alpha support, and features rather poor compression. Ideally it would have been entirely superceeded now either by the vastly superior
raster formats PNG and MNG or (for maps, diagrams and other such "drawn" things) by the scalable vector graphics format. PNG support is essentially universal in modern
browsers, and both MNG and SVG are bubbling under nicely.
While the burn all gifs page flatly recommends "by switching your site to PNG, you encourage users to upgrade to PNG-capable browsers", this rather stern prescription leaves all too many innocents in its wake - there's still enough users who're
stuck (for technical or institutional reasons) in GIF-only browsers. Wise web developers (and me too) believe, rather, in making pages that "degrade gracefully". This leaves web page developers with something of a dilemma - either stick with the antique format yet again, or leave the poor innocents
who can't upgrade with a broken website. Whoever said HTML was portable?
It's possible (although tricky and rather non-portable) to pick up image information from a CSS stylesheet, and it's possible (although tricky, very non-portable, and frequently disabled) to use DHTML (i.e. JavaScript and some DOM other other) to alter images according to browser capabilities.
Lastly one can dodge the client issue altogether and generate the appropriate webpage on the fly in the webserver - but using expensive server resources is a rather expensive and troublesome solution, particularly to a problem that should be trivial to solve on the client.
What we really need is a fix to the markup that defines images, which presently looks something like this:
<img src="foo.gif"
width=100
height=20>
If browsers supported image markup that allowed us to define a number of images (with some ordered notion of preference) and let the browser load and display the best one it is able to. So a first-cut at this might look something like this:
<img src="foo.gif"
width=100
height=20
newsrc="foo.png">
This second version is better, as it allows newer browsers to support enhanced functionality (a newer file format, in this case) without messing things up for folks stuck in antique browser land. We have to be careful, however, not to just defer the problem into the future - if (as is bound to
happen) a third (fourth, fifth...) format becomes available in a few years - do we either condemn future web designers again to the same hard choice as above?
Naively, one could fix the problem incrementally (for some amazing new 2009 era file format "FUF"):
<img
src="foo.gif" width=100 height=20
newsrc="foo.png"
newnewsrc="foo.fuf">
Naturally, the above isn't really much of a solution for anything. It's altogether better to solve the problem in one go, by specifying a list of available files, and letting the browser pick the first one (scanning left-to-right in the list) that it can support:
<img src="foo.gif"
width=100
height=20
newsrc="foo.fuf|image/fuf#foo.png|image/png">
Note that I cheated a bit above, by putting the mime types (image/fuf etc.) into the (pseudo)URI (which is naughty, to say the least) but it means the client doesn't have to parse the filename (which is itself naughty) or load the file (which is inexcusable) just to figure out it can't support
that format.
This approach (or something more general, ideally with better thought-out syntax) also solves that perennial browser-author issue "what's the point in our supporting it before IE does". That seems to be a significant part of the "do we include MNG" argument that the Mozilla folks are
going through right now (see mozilla bug 18574).
Blog: CSS layout after all [Saturday 13rd September 2003]
I spoke too soon. After much hand-wringing and chicken sacrifice, this version of the homepage does use a CSS only layout. It seems to work acceptably even in IE6 (sorry, I don't have access to IE5 or 5.5, so please let me know if things go weird in those browers).
Better yet, the page degrades gracefully, so it should be much more accessible for visitors with screen readers and text-only browsers.
Blog: New homepage look [Thursday 31st July 2003]
I've redesigned the homepage of the website quite radically. The old homepage was a dreadful anachronism which dated from the days when I really had no idea how to write decent HTML layout code. Hopefully this new version looks stylish and sells the website's contents better
(to the casual visitor) than did its rather amateurish predecessor.
I really wanted to change from using a table layout to an entirely CSS layout. Written properly, a CSS layed out page can degrade much better than the usual table-based solution that's the current state of the internet. This would provide a simple and usable page for disabled users and
those using limited access devices (like TV set-tops and cellphones). The villain of the piece is, as always, Microsoft. IE6's handling of percentages in CSS layouts differs from the other modern browsers (Netscape/Mozilla,
Konqueror/Safari, and Opera). I'm being generous here - really IE6's CSS layout code is broken. I'd love to either not cater for visitors for IE6, or at least give them
a crappy experience, but the grim fact of the matter is that around 90% of my visitors (poor misguided innocents that they are) still use either IE6 or or (jeepers) IE5.5.
So I have a plea for moderately technical visitors who're still running Microsoft Internet Explorer - web authors and sad disabled children the world over beg you to try another browser.
For mac users, try Safari or Mozilla.
For windows users, try Mozilla or Opera
Better yet, all of these browsers are free to download and they're all better than Internet Explorer, faster than Internet Explorer, and more standards compliant than Internet Explorer. Users of these browsers also have a lowered rate of gonadic atrophication.
Honest.
[ perhaps I should explain: "mozilla" is exactly the same as the Netscape browser, just with Netscape's advertising stuff removed ]
Blog: mcwalter.org has moves to an exciting, if rather wet, new home [Sunday 27th July 2003]
This website (which can be accessed from
http://www.mcwalter.org or
http://www.mcwalter.net) has recently moved home.
It was previously hosted by Yahoo! in the sunny Silicon Valley. For both technical and logistical reasons I've moved it to Plugsocket Internet, so this page is now being served from the dank East Anglian fen in the low
eastern part of southern England. If you remember that "dead marshes" place in the second Lord of the Rings movie? East Anglia's just like that.
Perhaps it's my imagination, but things seem to run much faster from the new location. If you're looking for a decent low-cost web hosting solution, and you don't need the handholding that providers like Yahoo! provide, I can heartily recommend Plugsocket.
2002
Blog: Bay to Breakers [Monday 20th May 2002]
Bay to Breakers (12k, hilly) across San Francisco.
01:38:28; wet. Damn that's a hill.
2001
Blog: Run to the Far Side [Sunday 25th November 2001]
Run to the Far Side XVII (3.1 miles) 31 minutes, San Francisco. There's a bunch of people dressed as Far Side characters - the chap dressed as an insanely tall lost giraffe picture on a milk carton did frighteningly well. This is my first real run (I'm much more of a swimmer)
and when I got to what I thought was the end I really set to a sprint finish - only to realise this was the photography arch and I had a further half mile to go. Oops.
2000
Blog: Stupid idea - exploding picnic baskets [Thursday 16th November 2000]
Bears that natively inhabit a number of the national parks in the western states of the U.S. are, like their T.V. counterpart Yogi, getting to be particularly fond of foraging for human food, rather than eating their natural diet. This is a problem both for the bears (who'll
probably get heart-disease or indigestion or something) and for the human park visitors (whose tents, cars and camping equipment bear witness (sic) to the awesome destructive power of a junk-food-obsessed ursine).
The idea
As with other things marked "stupid idea", I'm not really serious about this, so don't send me angry emails saying its a wicked idea. I know.
The current range of countermeasures employed by rangers to discourage this is varied, and increasingly ineffective, not least because bears are so smart that they can soon figure out their own countermeasures to the ranger's schemes (who says cartoons aren't just like real life?). The rangers
tactic of last resort is to transport the bears to areas with fewer campers. Sometimes the bears come back.
This idea proposes to exploit the bear's natural intelligence rather than trying to work around it. The bears need to be discouraged from molesting vehicles and camping equipment - once this is achieved the mother bears will teach their cubs to avoid campers (just as now they presently teach
them quite the opposite). So, how to you discourage a giant, nearly invulnerable, omnivore - and do so in a way that their pretty smart brains won't easily figure a way round?
The technology for this already exists, and can be adapted to anti-bear applications with a minimum of effort. Police, para-military and military forces around the world regularly use non-lethal stun grenades (also known as flashbangs) which generate an exceptionally loud explosion and
simultaneously a brilliant, blinding flash of light. The intention is to render terrorists and other miscreats temporarily insensate, allowing the user of the flashbang to overpower his opponent without resorting to lethal force. The effect of a flashbang detonation on a bear's acute sensory system
will likely be equally profound, and bears are very likely to avoid repeated exposure, or the chance thereof.
So, it should be possible to place a flashbang in a specially prepared picnic-basket, tent, vehicle or other human-related setting. The booby-trapped device can be labeled with a warning sign, so that campers who chance upon the site don't inadvertently set it off themselves (surely the only way
bears can figure out a way around this would happen when they learn to read - at which point the bastards can quit lounging around in the forest and can get proper jobs like the rest of us have to). The trap can optionally be baited with some particularly enticing foodstuffs, the smell of which
will attract any bear bold enough. When the bear tries to open the boobytrapped item, the flashbang would detonate, giving the bear a terrible shock and leaving it disoriented and probably nauseous. Any bear unfortunate enough to encounter this on a couple of occasions will soon associate human
food with great discomfort, and will soon return to their pastoral lives eating nuts and berries or whatever.
Why this isn't such a good idea
- The most consistently stupid mammal is the human being, and consequently no amount of warning signs, prior disclosure or visitor education will prevent some dumbo from suing when he's victimised by a trap intended to fool an animal that's allegedly only half as smart as he.
- In the more straightforward implementations of the flashbang boobytrapped items, the flashbang detonation will occur very close to the bear's head. In normal (e.g. antiterrorist) applications a flashbang is intended to be detonated in a room, ideally a short distance from its target. The
consequences of the bear's increased proximity to the explosion might be that it could suffer permanent damage to its eyes or ears - this is particularly likely in cases where immature bears or cubs are involved. With this in mind, the trap wsa to be designed to keep the flashbang away from the
trigger.
- This scheme creates some pressure for the bears to switch from eating human foods to eating humans. It's pretty hard to make a fake flashbang-exploding-human that will fool the average bear, so this scheme could have a rather nasty counterfinal effect.
But it's not just me
Park rangers and other woodsman-types are trying to figure out any number of ways to discourage bears from foraging for human food. At one time the recommendation was to spray pepper-spray around ones encampment. People did this for a time, until some researchers observed bears that seemed to
enjoy the pepper-sprayed area. In retrospect, using the pepper spray turned out to be about as smart as walking naked through the woods smeared with honey.





{kind=link}
{kind=link}
{kind=link}
{kind=link}